Meltdown и Spectre. Разбираем фундаментальные уязвимости в процессорах - «Новости»
12-01-2018, 12:00. Автор: Клара

Содержание статьи
- Бомба замедленного действия
- Spectre
- Реакция вендоров и патчи-костыли
- Почему все патчат ОС, драйверы и приложения, если проблема в процессорах?
Корень проблемы
Изначально в блоге Google Project Zero сообщалось об успешной реализации трех вариантов атаки на кеш процессора:
- злонамеренная загрузка?данных в кеш;
- обход границ массива;
- инъекция целевой ветви.
Формально их описали как две сходные уязвимости — Meltdown (первый вариант атаки) и Spectre (второй и третий варианты). Сценарии их практического использования зависят от микроархитектуры ЦП и операционной системы, в разной степени?затрагивая производителей железа, облачных провайдеров и сообщество Linux.
Авторы исследования знали о проблеме давно. 1 июня 2017 года они отправили свои отчеты в Intel, AMD и ARM, пообещав не публиковать детали до тех пор, пока разработчики не выпустят патчи. Однако произошла?утечка информации, из-за которой им пришлось обнародовать подробности раньше.
Уязвимости имеют много сходных черт на концептуальном уровне. Обе делают возможным проведение атаки по стороннему каналу, используя недостатки физической реализации процессоров. Впервые данный класс атак подробно описал Пол?Кёхер (Paul Kocher) еще в 1996 году применительно к популярным криптосистемам. Он также выступил соавтором исследования Meltdown и Spectre.
На сегодня продемонстрировано три базовых сценария использования этих уязвимостей, которые мы подробнее разберем ниже. Важно то, что во всех вариантах конечной?целью атак является кеш. Разными уловками процессор вынуждают кешировать значение байта из адреса памяти, недоступного вредоносному процессу.
Обрати внимание: зловред не считывает сами данные (он не может читать кеш в произвольном месте). Вместо этого он вычисляет ошибочно?закешированные байты уже в своем адресном пространстве, просто измеряя задержки чтения в разных строках заранее созданного массива.
По сути Meltdown и Spectre — это разновидность атаки по времени. Основная разница между ними состоит в том, как они вызывают кеширование данных из?защищенных страниц памяти. Meltdown пользуется задержкой в обработке исключения, а Spectre обманывает блоки предсказания. Чтобы понять эти детали, нужно освежить в памяти базовое устройство процессора.
Бомба замедленного действия
Сама идея внеочередного исполнения инструкций была предложена IBM в 1963 году. Рядовые пользователи?столкнулись с ней только в 1995 году, когда появился первый Pentium Pro. С тех пор линейный конвейер канул в Лету, а все современные процессоры используют архитектуру с внеочередным (out-of-order) и одновременно упреждающим (или спекулятивным — speculative) механизмом исполнения команд.
Как же это работает? Для программиста все?выглядит просто. Он отправил очередь инструкций на вход и получил ее исполнение на выходе. Однако внутри процессора творится своя магия. Современное процессорное ядро использует многоуровневый конвейер с нелинейными путями. Все входящие инструкции в нем кешируются и декодируются по нескольку штук за такт. Они дробятся на микрооперации, которые переупорядочиваются в собственном буфере (ROB, Re-Order Buffer). Ни одна из?них не работает с реальными адресами памяти и физическими регистрами процессора. Блок управления памятью транслирует виртуальные адреса и определяет параметры доступа к ним.
После ROB микрооперации отправляются в станцию резервации, где обрабатываются параллельно на?разных исполнительных блоках. Вдобавок современные процессоры используют разные типы кешей для ускорения обработки данных, изначально загружаемых в не слишком быструю оперативную память. Простейший кеш для инструкций применялся еще в 1982 году, а кеш данных используется с 1985 года. Сейчас они оба относятся?к базовому кешу первого уровня (L1), помимо которого появились L2 и L3 общего назначения.
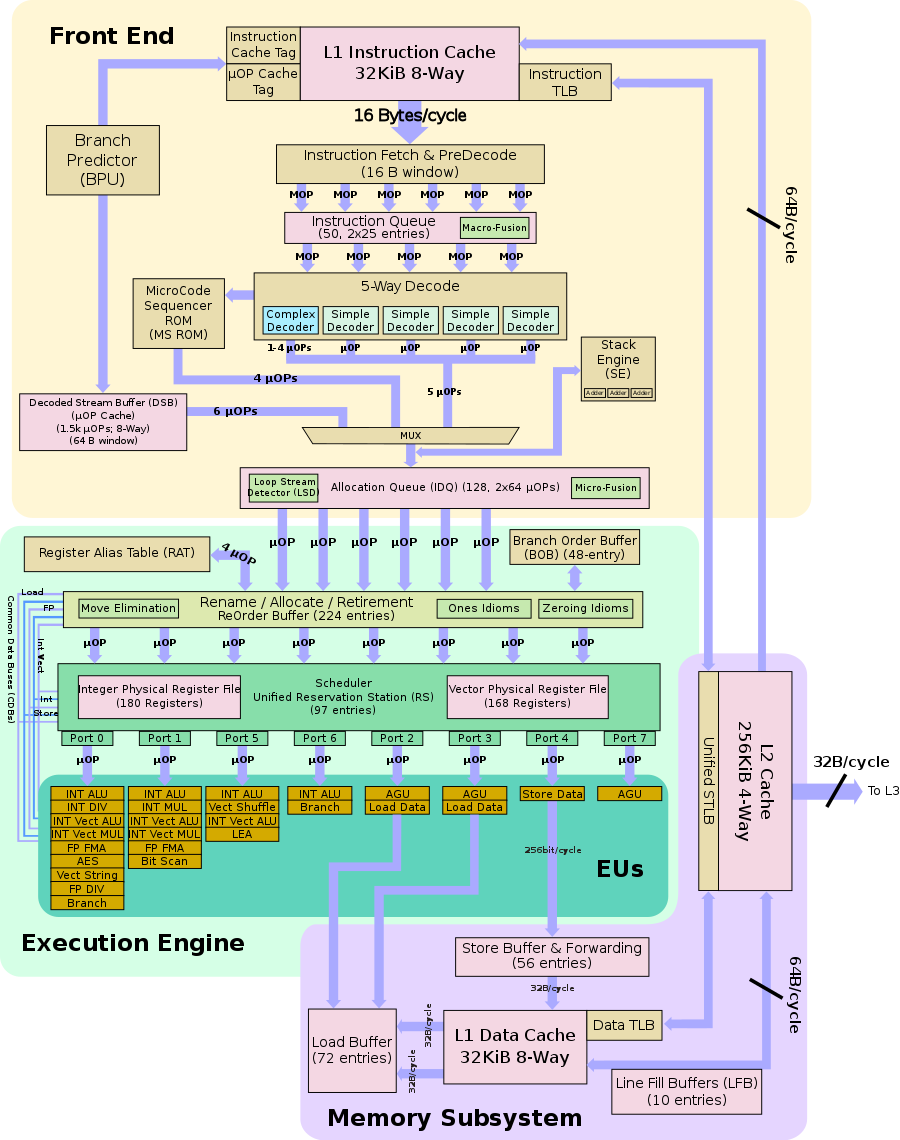
Блоковая диаграмма конвейера Intel Skylake / Kaby Lake (источник: wikichip.org)
Все эти архитектурные навороты создавались для уменьшения времени простоя отдельных исполнительных блоков процессора. Пока один блок ожидает загрузки?данных из оперативной памяти для своей инструкции, другой параллельно обрабатывает следующие. В этом ему помогает MMU (Memory Management Unit) и общая архитектура конвейера, который старается работать на упреждение и постоянно подгружает наиболее востребованные данные в?кеш.
Ключевой момент в этой схеме состоит в том, что в большинстве процессоров все проверки легитимности исполнения инструкций и даже контроль за разделением доступа к памяти в?самом MMU происходят уже на заключительном этапе обработки инструкций, когда начинается выстраивание промежуточных результатов в порядке исходной очереди команд. Запрещенные операции игнорируются (вызывают исключение), а невостребованные данные при этом остаются?в кеше. Собственно, это и есть главная проблема.
В большей мере задержками в проверке условий и длинным забеганием вперед по ветвям инструкций грешат процессоры Intel с длинным конвейером (кроме Itanium и первых Atom), но AMD и даже ARM это?тоже касается — просто в эксплоитах для них потребуется более точный таймер, другие размеры массивов и техники забивания кеша. Если Meltdown для них пока не смогли убедительно воспроизвести, то Spectre — вполне.
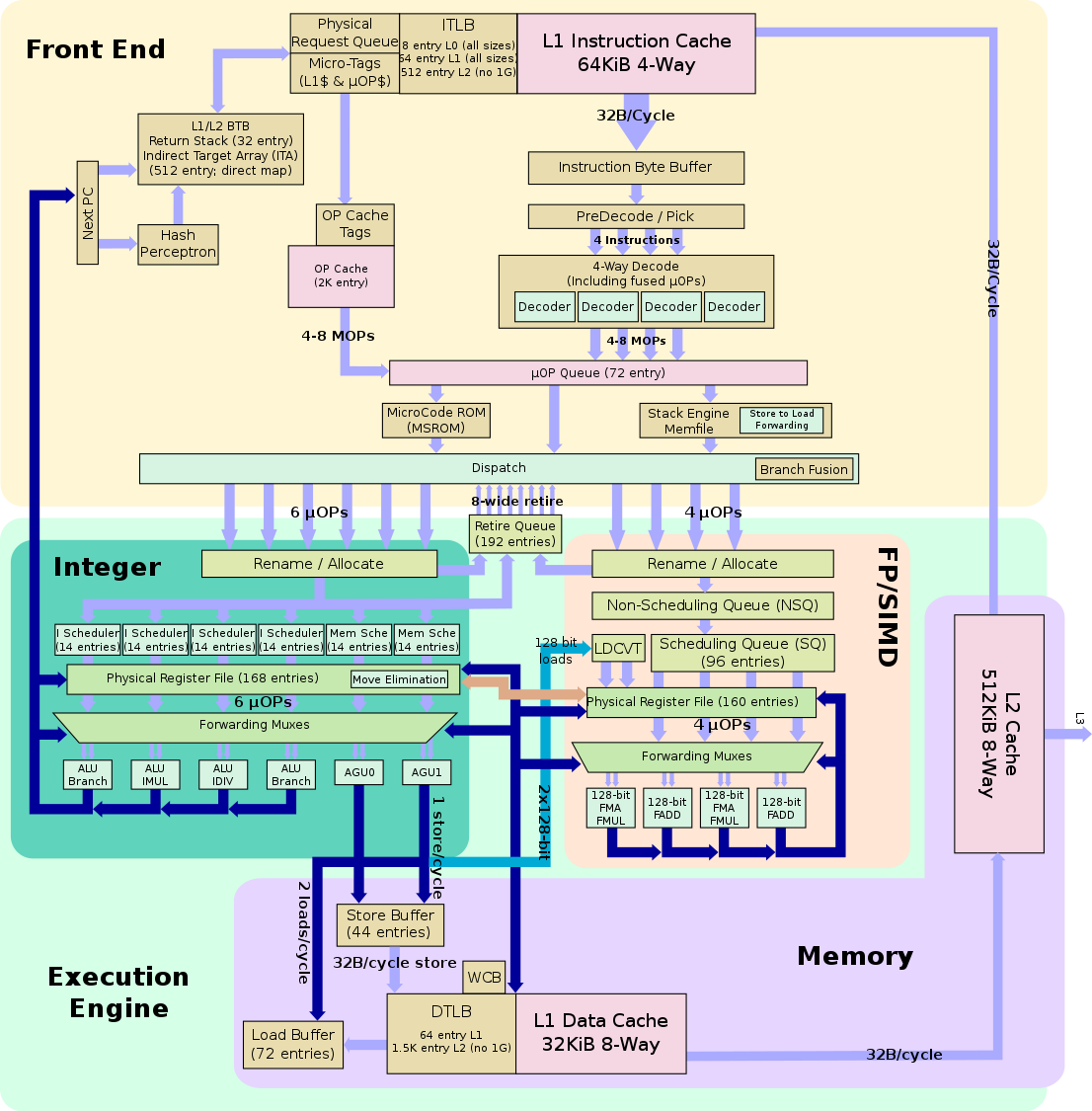
Блоковая диаграмма?конвейера AMD Zen (источник: wikichip.org)
Целых 27 лет ведущие разработчики считали, что скорость обработки инструкций важнее безопасности, а все проверки можно делать уже после пробного исполнения команд «на выходе» из конвейера. В том или ином виде внеочередное исполнение сегодня реализовано во всех процессорах. Из-за параллельной работы исполнительных блоков задержка в обработке исключения, лаг MMU и очистки кеша тоже есть всегда, просто в случае микроархитектуры Core они?заметнее и ими проще воспользоваться.
Перейти обратно к новости