Выносим всё! Какие данные о нас хранит Google и как их вернуть себе через Takeout - «Новости»
20-04-2018, 15:01. Автор: Инесса

Содержание статьи
- Чаты
- Карты
- My Activity
- Выводы
Причины взять и забрать всё могут быть разными. Например, ты хочешь мигрировать на другой сервис и перенести туда свои данные: без конвертации вряд ли обойдется, но иногда это?оправданная морока. Или, может быть, ты хочешь сделать какую-то аналитическую систему в духе лайфлоггинга и quantified self и тебе в этом помогут накопленные в Google данные. Или страна, в которой ты живешь, вдруг решила отгородить свой интернет каким-нибудь великим файрволом, после чего Google окажется за бортом. Увы, бывает и?такое.
Я за последние двенадцать лет немало пользовался продуктами Google, тестируя многие из них в рамках обзоров, и никогда не выключал следящие механизмы. Возможно, ты скажешь, что это безумие, но, во-первых, Google относится к моим данным бережно и?причин для паники пока не давал, а во-вторых, я ни в коем случае не пропагандирую такой подход. Так что считай, что я терплю этот кошмар, чтобы тебе не пришлось! ?
Итак, чтобы получить свои архивы, нужно?зайти в окошко по адресу takeout.google.com, выставить галочки напротив интересующих тебя сервисов и подождать некоторое (ощутимое) время. Когда я запросил полный архив, ссылка пришла через день, то есть больше чем через 24 часа. В письме робот Google бодро?сообщил, что данные собраны по 36 продуктам, занимают 63,6 Гбайт и разбиты по трем архивам. Причем основной объем пришелся на первые два, а третий оказался зазипованной страницей с каталогом всего выданного.
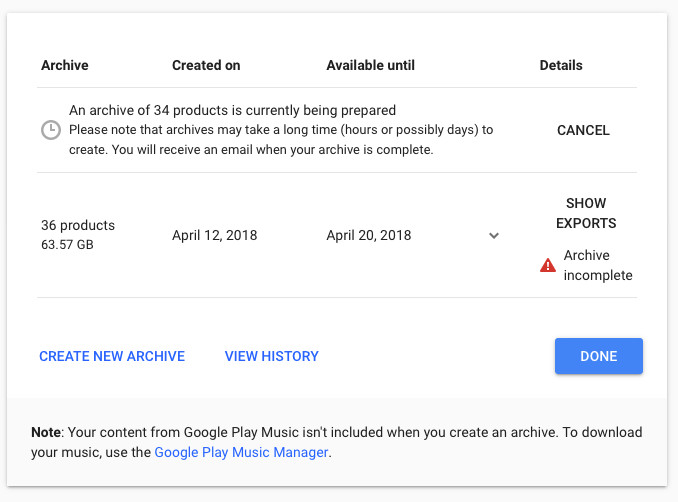
Если не хочешь качать такие?объемы, то заказывай частичные архивы, которые будут включать не все сервисы. Например, если выключить Photos, YouTube и Gmail, а также Drive, если ты там хранишь что-то помимо тестовых документов, то может получиться всего несколько сот мегабайтов. Кстати, чем меньше архив, тем быстрее приходит ссылка?на скачивание.
Поиск
Начнем с одной из самых занимательных вещей — истории поисковых запросов. Она лежит в папке Searches и разбита на файлы по три месяца, к примеру 2006-01-01 January 2006 to March 2006.json. Если откроешь один из них, то увидишь, что информация о каждом?запросе состоит всего из двух вещей: времени в формате Unix и искомой строки.
Для перевода времени можно использовать какой-нибудь онлайновый конвертер, а если нужно будет сконвертировать массово, то это делается одной строкой на Python (замени?слово «время» на свое значение):
datetime.datetime.fromtimestamp(int("время")).strftime('%d-%m%-%Y %H:%M:%S')
[/code]
Но подробным анализом я предлагаю тебе заняться самостоятельно. Мы же забавы ради попробуем поискать вхождения тех или иных строк при помощи grep. Поскольку данные сохранены в JSON, их сначала нужно будет сконвертировать в строки — я для этого использовал утилиту gron, о которой недавно писал в рубрике WWW.
Если у тебя установлен gron, можешь написать что-то в таком духе:
$ for F in *; do cat "${F}" | gron | grep "xakep"; done
И увидишь все свои запросы со словом xakep за все время. Какие еще ключевики?можно попробовать? Ну например, слово «скачать». ? Или вот занятная идея: если поискать символ @, то ты найдешь все почтовые адреса и аккаунты Twitter, которые ты пробивал через Google.
Обрати внимание, что здесь нет поиска по картинкам и видео, но мы их еще обнаружим?в папке My Activity.

WWW
Пост о том, как сконвертировать историю запросов в Excel и потом анализировать
Чаты
Возможно, у тебя уже где-то спрятана папка со старыми логами ICQ и ты бы хотел присовокупить к ней еще и все когда-либо?написанное через Google Talk и Hangouts. Это вполне реально, но, к сожалению, читать переписку в том виде, в котором она приходит из Takeout, практически невозможно (в отличие, кстати, от логов ICQ).
Весь текст экспортируется как единственный файл JSON плюс горка приложенных картинок — все это лежит в папке Hangouts. С картинками никаких проблем, а вот в JSON на?каждое написанное сообщение приходится порядка двух десятков строк метаданных. Но пожалуй, главная головная боль — в том, что вместо имени отправителя здесь ID пользователя.
Наверное, самое простое, что мы можем сделать, — это выкинуть всю мишуру и оставить только?текст. По крайней мере можно увидеть какие-то, пусть и обезличенные, беседы.
$ gron Hangouts.json | grep '.text'
Так хотя бы есть шанс что-то выловить.
Google+
Что действительно есть смысл бэкапить — это посты из социальной сети Google+, которая стремительно становится артефактом прошлого. Если ты, конечно, вообще когда-либо?ей пользовался.
Данные поделены на три папки: Google+ Stream, Circles и Pages. Давай заглянем в них по порядку.
Circles — это контакты людей, организованные по «кругам» из Google Plus. Формат — vCard (VCF) с той информацией, которую люди сами о себе заполнили. Можно при желании одним?махом импортировать в любую адресную книгу.
Папка Pages будет присутствовать в том случае, если у тебя имелись публичные страницы. Но ничего интересного там нет, разве что юзерпик и обложка страницы.
Также к данным Google+ стоит отнести папку Profile. В ней содержится JSON с копией?всех тех данных, что ты заполнил о себе в этой соцсети. Основные интересные вещи лежат в структурах urls (ссылки на другие профили в соцсетях) и organizations (места работы с датами). Забавная деталь: при том, что у меня в?профиле не указан возраст, здесь присутствует поле "ageRange": {"min": 21}, значение которого Google, кажется, определил самостоятельно.
Самое главное ты найдешь в папке Google+ Stream. Здесь в качестве отдельных HTML свалены все твои посты с комментариями и даже отдельные комментарии. Можно полистать и поностальгировать, а можно парой строк на Python с BeautifulSoup выдрать, к примеру, только тексты постов. Выбирать нужно будет элементы с классами entry-title и entry-content.
К сожалению, картинки из постов не бэкапятся автоматически — они так и остаются ссылками на сервер Google, который еще и не отдаст их без?авторизации. Недоработочка!
Перейти обратно к новости