Сам себе архивариус. Изучаем возможности ArchiveBox - «Новости»
3-02-2021, 00:00. Автор: Наталья
интернет‑архиве». Но туда выгружается далеко не все содержимое сайта: многие изображения, скрипты и видеоролики наверняка окажутся недоступны. Чтобы избежать подобных неприятностей, существует бесплатный инструмент ArchiveBox, о котором мы сегодня и поговорим.
Несмотря на то что «интернет‑архив» по праву считается одним из самых популярных инструментов поиска «потерянных» и удаленных веб‑страниц, он имеет ряд серьезных ограничений.
- Во‑первых, он не индексирует страницы в Facebook, «ВКонтакте» и других соцсетях.
- Во‑вторых, в веб‑архив попадают далеко не все разделы сайта.
- В‑третьих, туда не добавляются ресурсы и их разделы, закрытые от индексации соответствующей инструкцией в файле
robots.txt - В‑четвертых, в архив точно не попадут предназначенные для скачивания файлы, видео- и аудиоролики и прочие подобные элементы.
- Наконец, если отображаемый контент сайта динамически создается с помощью jаvascript или других подобных инструментов, при сохранении он может частично утратиться или «поломаться» — в результате копия веб‑страницы будет выглядеть совсем не так, как оригинал. То же самое, кстати, касается веб‑страниц, сохраняемых из интернета на локальной машине стандартными средствами браузера.
Напрашивается вывод: нужен альтернативный инструмент, который позволит создавать копию выбранных сайтов, причем сможет делать это быстро, качественно и надежно.
Именно для этого и был создан ArchiveBox. Он позволяет сохранить автономный дубликат любого сайта и выгрузить в архив все его содержимое. Целевые веб‑ресурсы можно задать по списку URL либо взять из закладок или истории браузера. Сайты будут выгружены вне зависимости от настроек robots., запрещающих индексацию. Вместе с веб‑страницами сохраняются картинки, встроенные видео, элементы jаvascript и прочее полезное содержимое.
Получается эдакий персональный «архив интернета», которым распоряжаешься и управляешь ты сам. Инструмент может быть полезен как в качестве альтернативы скачиванию веб‑страничек на собственный компьютер, так и для исследования заинтересовавшего тебя сайта — в архивной копии можно копаться сколько душе угодно, не опасаясь неожиданностей.
Полный текст этой статьи доступен без подписки благодаря спонсору — компании RUVDS, одному из самых передовых хостинг‑провайдеров VPS/VDS-серверов. RUVDS предлагает виртуальные серверы в десяти дата‑центрах уровня TIER3 и выше по всему миру, низкие цены от 30 рублей в месяц, удобный маркетплейс и установку популярных образов в один клик.
Установка
Движок ArchiveBox написан на Python, использует в своей работе Wget и curl и рассчитан на работу в среде Linux и macOS, где для него имеются все необходимые компоненты. Для запуска ArchiveBox в Windows можно использовать Docker — подробная инструкция по развертыванию образа есть на GitHub проекта. Мы же будем настраивать ArchiveBox в Linux, для чего используем виртуальный сервер: это обеспечит высокоскоростной канал связи с интернетом и должное быстродействие, одновременно избавив нас от необходимости городить огород с установкой виртуальной машины. В качестве операционной системы была выбрана Ubuntu 20.04 LTS (в этой версии Python включен в базовую поставку системы), но подойдет, в принципе, любой распространенный дистрибутив Linux.
Вот такую конфигурацию сервера мы выбрали для установки ArchiveBox
Итак, для ArchiveBox необходим прежде всего Python, поэтому для начала зайдем на сервер и посмотрим, какая версия установлена в нашей системе:
python3 -VНам нужна версия не ниже 3.7. Система радостно отрапортовала, что на сервере установлен Python 3.8.5, поэтому обновлять его не придется. Если же на твоей машине обитает престарелая змея, обновить версию можно командой sudo . Чтобы установить Python, используй команду sudo .
Проще всего установить ArchiveBox с помощью Pip — инструмента, позволяющего загружать пакеты Python из репозитория Python Package Index (PyPI). Если этот компонент отсутствует в системе, его необходимо сначала установить. Для этого выполним в терминале следующие команды:
sudo apt update
sudo apt-get install python3-pip
Обычно в комплекте с Python 3 идет модуль Pip 3, но на всякий случай давай проверим, какая версия Pip установлена в системе:
pip3
В нашем случае сервер отрапортовал, что версия имеет номер 20.0.2, и как минимум мы убедились, что pip3 в системе присутствует. Отлично, устанавливаем сам ArchiveBox:
pip3 install archivebox

Установка ArchiveBox
info
На локальной машине с Linux установку ArchiveBox нужно запускать с использованием sudo.
ArchiveBox не работает из‑под пользователя root, поэтому для него нужно создать отдельного юзера с помощью команды adduser . Теперь от имени уже этого пользователя создаем рабочую папку, в которую ArchiveBox будет складывать загруженные сайты:
mkdir archives && cd archives
archivebox init
На этом процедура установки и настройки инструмента закончена, можно переходить к его использованию.
Архивируем сайты
Все команды ArchiveBox имеют общий вид $ archivebox [command] [parameter], где command — непосредственно команда, а parameter — опциональный ключ. Для добавления сайта в архив служит команда add. Так, чтобы собрать подшивку нашего любимого журнала, нужно набрать в терминале
ArchiveBox автоматически создаст в своей рабочей папке субдиректорию archive, в которую будет складывать скачанные сайты — каждый в своей вложенной папке. В этой же папке будет создан файл index., куда добавляется общая информация о заархивированном сайте, числе собранных файлов и их типе. На локальной машине его можно открыть в браузере; если же мы используем VPS, этот файл нам не слишком поможет, зато мы сможем просмотреть содержимое папки с архивом в терминале.
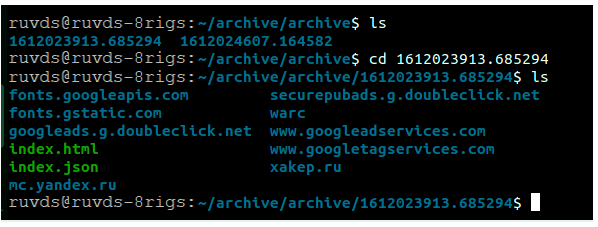
Содержимое рабочей папки ArchiveBox
По умолчанию ArchiveBox сохраняет в архив только веб‑страницу, указанную в заданном URL. Но можно заставить его выполнить рекурсивный обход всех ссылок на этой странице с указанной глубиной просмотра и добавить туда все, что по этим самым ссылкам будет найдено. Для этого служит параметр --depth=N, где N — глубина просмотра ссылок. Например, для того чтобы ArchiveBox заархивировал главную страницу сайта и все страницы, ссылки на которые присутствуют на главной, можно использовать команду
Поскольку мы архивируем сайты на сервер VPS, добычу нужно предварительно скачать на локальную машину с использованием scp или любым другим удобным способом. Можно, например, установить на сервере vsftpd и получить доступ к содержимому архивов по FTP непосредственно из браузера либо с помощью любого FTP-клиента. А еще можно поднять там Apache и переместить содержимое архивов в домашнюю папку веб‑сервера, чтобы просматривать их по HTTP.
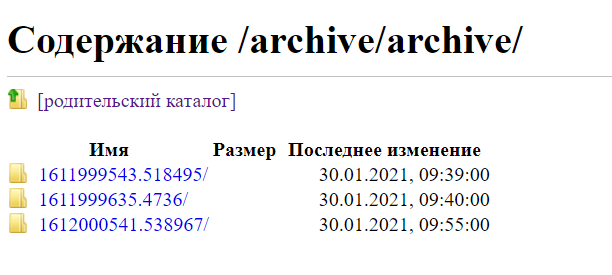
Содержимое архива, доступное по FTP
В результате выполнения команды archivebox сайт сохраняется вместе со всем содержимым, включая скрипты, изображения, CSS-файлы.
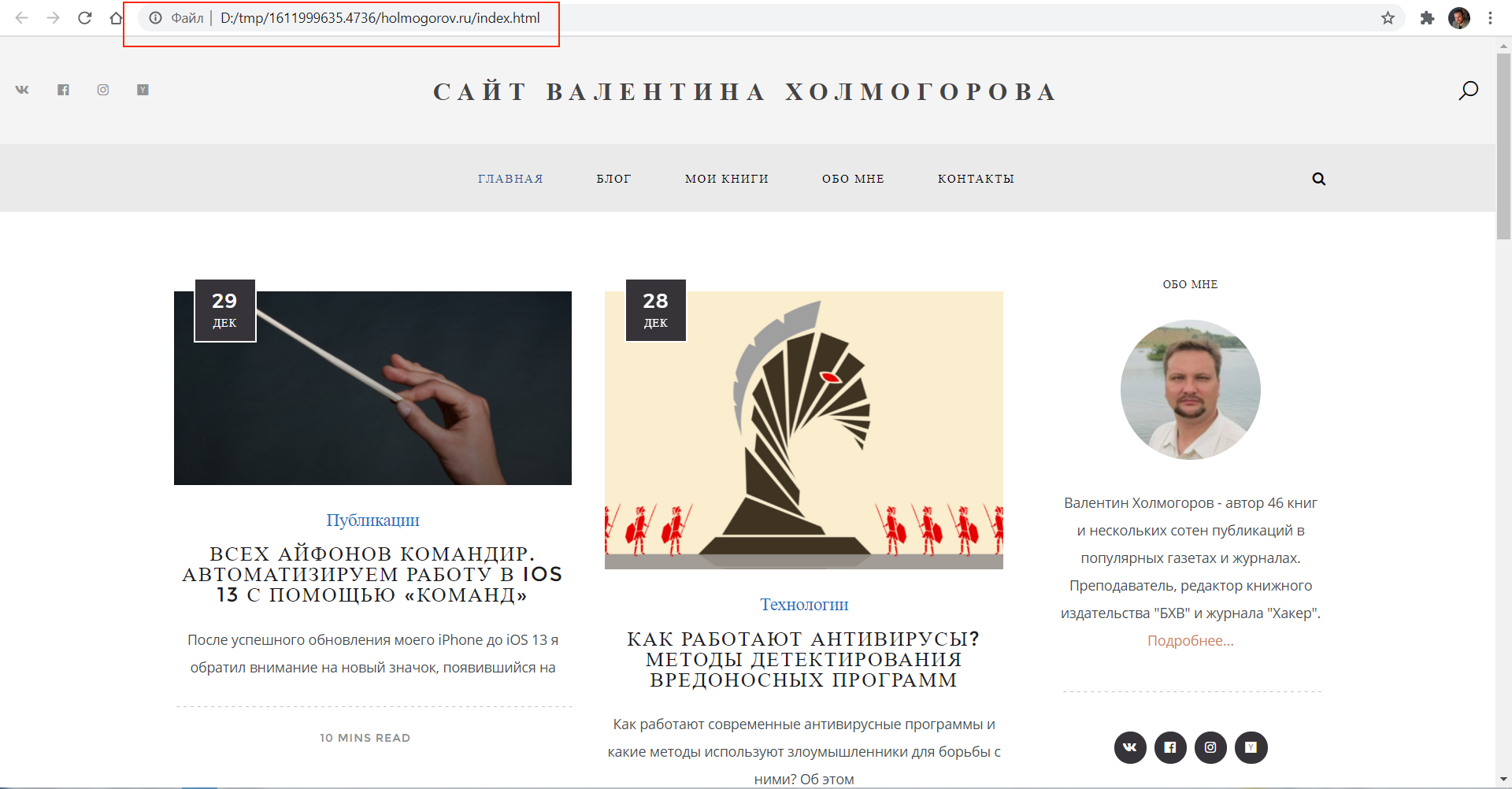
Архивный сайт, доступный локально после загрузки с сервера
ArchiveBox использует консольную утилиту youtube-dl для сохранения видео, благодаря чему он может тянуть ролики с этого популярного видеохостинга. Для их скачивания используется та же команда, с помощью которой сохраняются все остальные сайты:
Пакетная архивация сайтов
ArchiveBox также позволяет скачивать несколько сайтов по списку, заданному в текстовом файле. Чтобы использовать эту возможность, создай простой текстовый файл, например с именем urls., и запиши в нем адреса сайтов, которые хочешь скачать, — каждый адрес с новой строки. На удаленном сервере это можно сделать с помощью редактора nano:
nano urls.txt
Затем останется лишь «скормить» этот файл архиватору:
Есть у ArchiveBox еще одна возможность: если импортировать закладки браузера в HTML-файл, а потом загрузить его на сервер (при использовании ArchiveBox на локальной машине с линуксом этого не потребуется), то такой файл тоже может служить списком URL для архивации. В этом случае нужно использовать следующую команду:
Выводы
В качестве инструмента для копирования интернет‑контента ArchiveBox довольно удобен. С его помощью можно сохранять как отдельные страницы, так и целые разделы сайтов для последующего изучения на локальной машине или на виртуальном сервере, выполнять пакетную архивацию, а с помощью cron — копировать контент из сети по расписанию.
Безусловно, наиболее комфортно использовать ArchiveBox на локальной машине с Linux или macOS, но за неимением таковых сойдет и виртуальный сервер. ArchiveBox все еще находится в стадии разработки и непрерывно развивается, поэтому уже в недалеком будущем в его составе могут появиться новые функции и возможности. За обновлениями можно следить на страничке ArchiveBox на GitHub.
Перейти обратно к новости