Эксплуатация ядра для чайников. Проходим путь уязвимости от сборки ядра Linux до повышения привилегий - «Новости»
14-06-2021, 00:02. Автор: Ефросинья
tar xaf linux-5.12.4.tar.xz и заходим в появившуюся папку.Конфигурация
Мы не будем делать универсальное ядро, которое может поднимать любое железо. Все, что нам нужно, — это чтобы оно запускалось в QEMU, а изначальная конфигурация, предложенная разработчиками, для этих целей подходит. Однако все‑таки необходимо удостовериться, что у нас будут символы для отладки после компиляции и что у нас нет стековой канарейки (об этой птице мы поговорим позже).
Существует несколько способов задать правильную конфигурацию, но мы выберем menuconfig. Он удобен и нетребователен к GUI. Выполняем команду make и наблюдаем следующую картину.
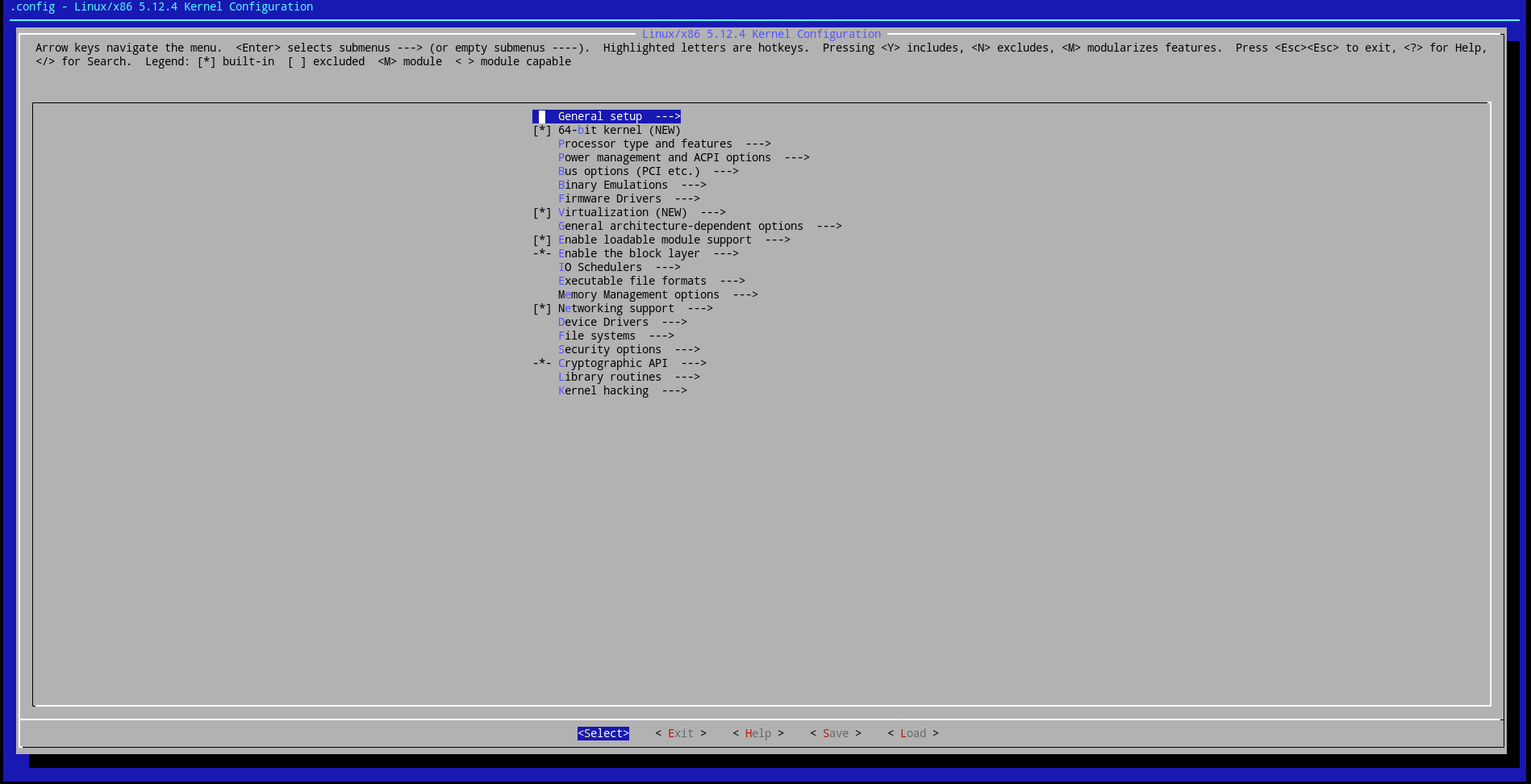
Для того чтобы у нас появились отладочные символы, идем в секцию Kernel hacking → Compile-time checks and compiler options. Тут надо будет выбрать Compile the kernel with debug info и Provide GDB scripts for kernel debugging. Кроме отладочных символов, мы получим очень полезный скрипт vmlinux-gdb.. Это модуль для GDB, который поможет нам в определении таких вещей, как базовый адрес модуля в памяти ядра.
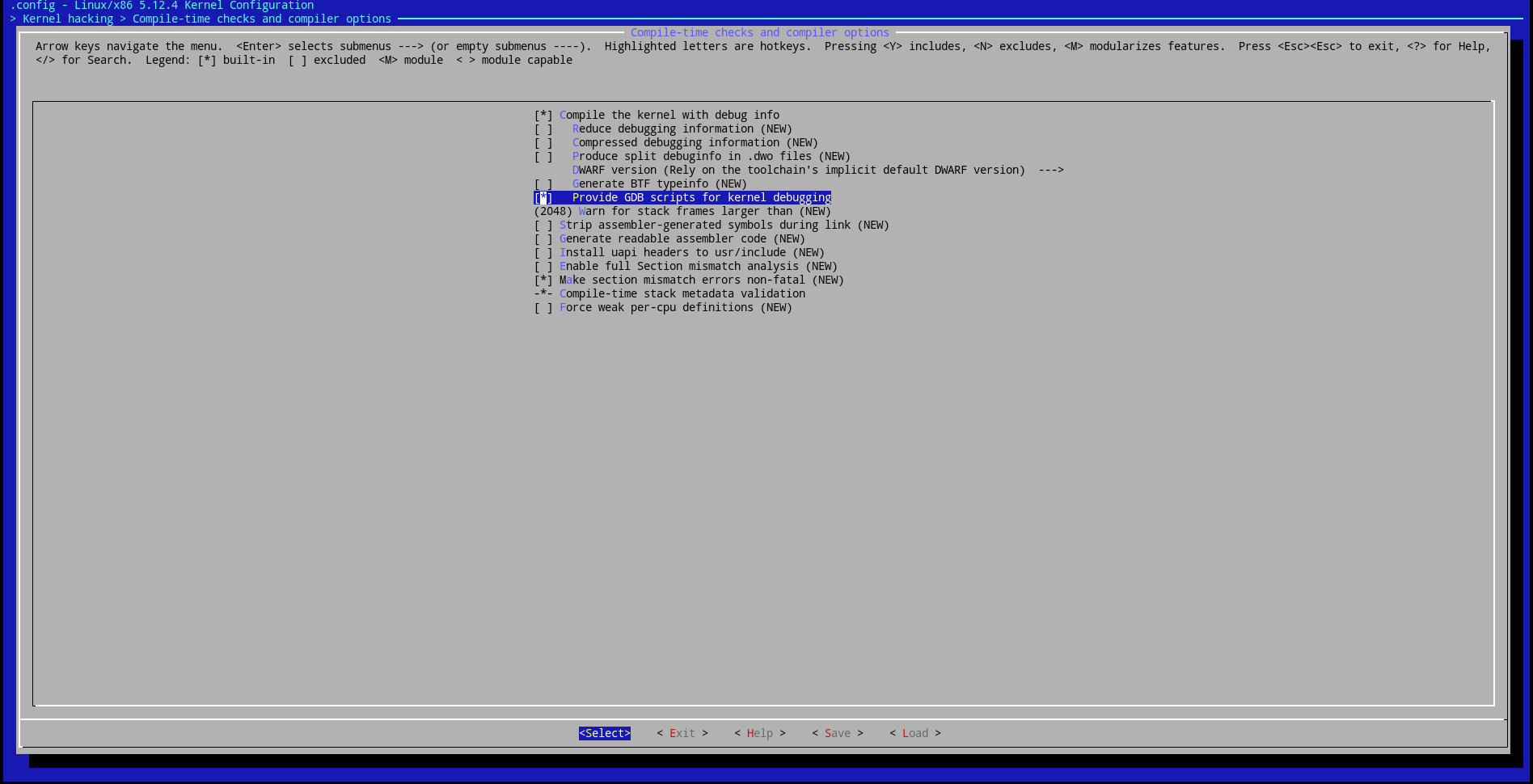
Теперь надо убрать протектор стека, чтобы наш модуль был эксплуатируем. Для этого возвращаемся на главный экран конфигурации, заходим в раздел General architecture-dependent options и отключаем функцию Stack Protector buffer overflow detection.
Можно нажать на кнопку Save и выходить из окна настройки. Что делает эта настройка, мы увидим далее.
Сборка ядра
Тут совсем ничего сложного. Выполняем команду make , где threads — это количество потоков, которые мы хотим использовать для сборки ядра, и наслаждаемся процессом компиляции.
Скорость сборки зависит от процессора: около пяти минут она займет на мощном компьютере и намного дольше — на слабом. Можешь не ждать окончания компиляции и продолжать читать статью.
Модуль ядра
В ядре Linux есть такое понятие, как character device. По‑простому, это некоторое устройство, с которым можно делать такие элементарные операции, как чтение из него и запись. Но иногда, как ни парадоксально, этого устройства в нашем компьютере нет. Например, существует некий девайс, имеющий путь /, и, если мы будем читать из этого устройства, мы получим нули (нуль‑байты или x00, если записывать в нотации C). Такие устройства называются виртуальными, и в ядре есть специальные обработчики на чтение и запись для них. Мы же напишем модуль ядра, который будет предоставлять нам запись в устройство. Назовем его /, а функция записи в это устройство, которая вызывается при системном вызове write, будет содержать уязвимость переполнения буфера.
Код модуля и пояснения
Создадим в папке с исходным кодом ядра вложенную папку с именем vuln, где будет находиться модуль, и поместим там файл vuln. вот с таким контентом:
#include <linux/kernel.h>#include <linux/fs.h>#include <linux/kdev_t.h>#include <linux/device.h>#include <linux/cdev.h>MODULE_LICENSE("GPL"); // Лицензияstatic dev_t first;static struct cdev c_dev;static struct class *cl;static ssize_t vuln_read(struct file* file, char* buf, size_t count, loff_t *f_pos){return -EPERM; // Нам не нужно чтение из устройства, поэтому говорим, что читать из него нельзя}static ssize_t vuln_write(struct file* file, const char* buf, size_t count, loff_t *f_pos){char buffer[128];int i;memset(buffer, 0, 128);for (i = 0; i < count; i++){*(buffer + i) = buf[i];}printk(KERN_INFO "Got happy data from userspace - %s", buffer);return count;}static int vuln_open(struct inode* inode, struct file* file) {return 0;}static int vuln_close(struct inode* inode, struct file* file) {return 0;}static struct file_operations fileops = {owner: THIS_MODULE,open: vuln_open,read: vuln_read,write: vuln_write,release: vuln_close,}; // Создаем структуру с файловыми операциями и обработчикамиint vuln_init(void){alloc_chrdev_region(&first, 0, 1, "vuln"); // Регистрируем устройство /devcl = class_create( THIS_MODULE, "chardev"); // Создаем указатель на структуру классаdevice_create(cl, NULL, first, NULL, "vuln"); // Создаем непосредственно устройствоcdev_init(&c_dev, &fileops);
// Задаем хендлерыcdev_add(&c_dev, first, 1); // И добавляем устройство в системуprintk(KERN_INFO "Vuln module startedn");return 0;}void vuln_exit(void){ // Удаляем и разрегистрируем устройствоcdev_del( &c_dev );device_destroy( cl, first );class_destroy( cl );unregister_chrdev_region( first, 1 );printk(KERN_INFO "Vuln module stopped??n");}module_init(vuln_init); // Точка входа модуля, вызовется при insmodmodule_exit(vuln_exit); // Точка выхода модуля, вызовется при rmmodЭтот модуль создаст в / устройство vuln, которое будет позволять писать в него данные. Путь у него простой: /. Любопытный читатель может поинтересоваться, что за функции остались без комментариев? Их значение можно поискать вот в этом репозитории. В нем, скорее всего, отыщутся все функции, на которые есть документация в ядре Linux в виде страниц man.
Уязвимость
Обрати внимание на функцию vuln_write. На стеке выделяется 128 байт для сообщения, которое будет написано в наше устройство, а потом выведется в kmsg, устройство для логов ядра. Однако и сообщение, и его размер контролируются пользователем, что позволяет ему записать намного больше, чем положено изначально. Здесь очевидно переполнение буфера на стеке, с последующим контролем регистра RIP (Relative Instruction Pointer), что позволяет нам сделать ROP Chain. Мы поговорим об этом в разделе, посвященном эксплуатации уязвимости.
Сборка модуля
Сборка модуля достаточно тривиальная задача. Для этого в папке с исходным кодом модуля надо создать Makefile вот с таким контентом:
all:
make -C ../ M=./vuln # Вызвать главный Makefile с аргументом M=$(module folder), чтобы он собрался
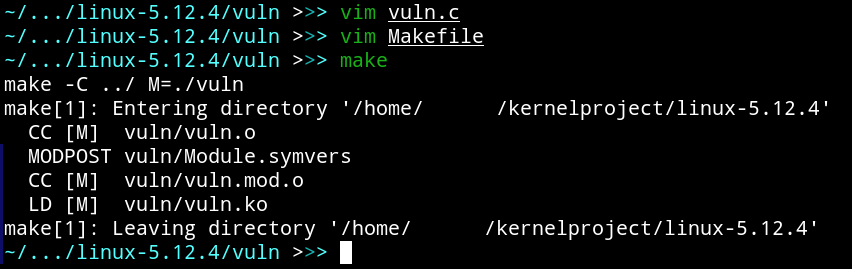
После этого в папке появится файл vuln.. Расширение ko означает Kernel Object, он несколько отличается от обычных объектов .. Получается, мы уже собрали ядро и модуль для него. Для запуска в QEMU осталось проделать еще несколько операций.
Rootfs
Вопреки распространенному мнению, Linux не является операционной системой, если рассматривать его как отдельную программу. Это лишь ядро, которое в совокупности с утилитами и программами GNU дает полноценную рабочую РС. Она, кстати, так и называется — GNU/Linux. То есть если ты запустишь Linux просто так, то он выдаст Kernel panic, сообщив об отсутствии файловой системы, которую можно принять за корневую. Даже если таковая есть, ядро первым делом попытается запустить init, бинарник, который является главным процессом‑демоном в системе, запускающим все службы и остальные процессы. Если этого файла нет или он работает неправильно, ядро выдаст панику. Поэтому нам нужен раздел с userspace-программами. Далее я буду использовать pacstrap, скрипт для установки Arch Linux. Если у тебя Debian-подобная система, ты можешь использовать debootstrap.
Возможные варианты
Существует много разных вариантов собрать полностью рабочую систему: как минимум, есть LFS (Linux From Scratch), но это уже слишком сложно. Также есть вариант с созданием initramfs (файл с минимальной файловой системой, необходимый для выполнения некоторых задач до загрузки основной системы). Но минус этого способа в том, что такой диск не очень просто сделать, а редактировать еще сложнее: его придется пересобирать. Поэтому мы выберем другой вариант — создание полноценной файловой системы ext4 в файле. Давай разберемся, как мы будем это делать.
Создание диска
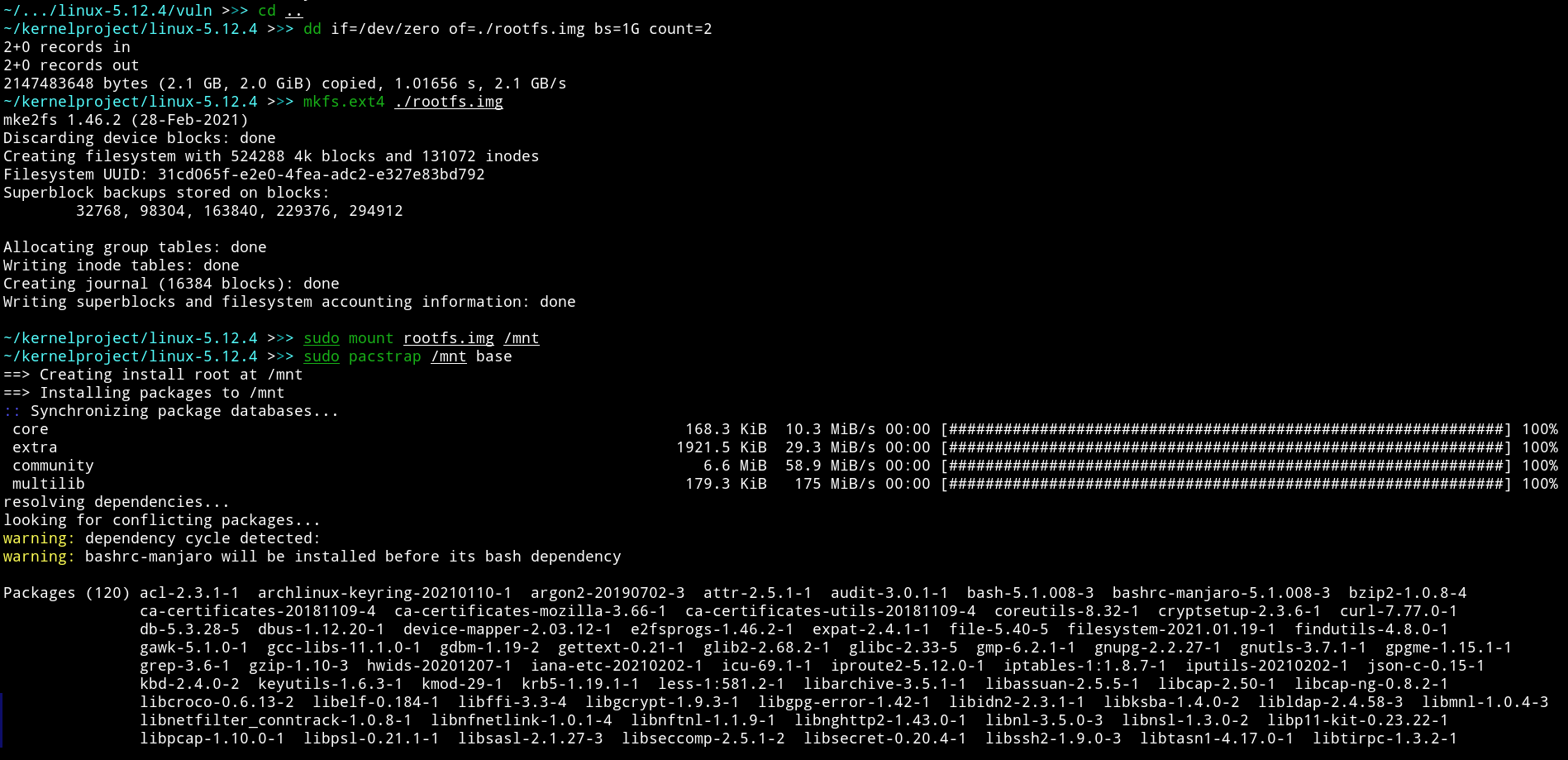
Для начала надо отвести место под саму файловую систему. Для этого выполним команду dd . Данная команда заполнит rootfs. нулями, и установим его размер в 2 Гбайт. После этого надо создать раздел ext4 в этом файле. Для этого запускаем mkfs.. Нам не требуются права суперпользователя, потому что файловая система создается в нашем файле. Теперь остается последнее, что мы сделаем перед установкой системы: sudo . Теперь права суперпользователя нам понадобятся для того, чтобы смонтировать эту файловую систему и делать манипуляции уже в ней.
Установка Arch
Звучит страшно. На самом деле, если речь идет о Manjaro или другой Arch Linux подобной системе, все крайне просто. В репозиториях имеется пакет под названием arch-install-scripts, где находится pacstrap. После установки данного пакета выполняем команду sudo и ждем, пока скачаются все основные пакеты.
Потом надо будет скопировать vuln. командой
cp<kernel sources>/vuln/vuln.ko /mnt/vuln.ko
Модуль в системе, все хорошо.
Небольшая конфигурация изнутри
Теперь нам нужно настроить пароль суперпользователя, чтобы войти в систему. Воспользуемся arch-chroot, который автоматически подготовит все окружение в созданной системе. Для этого запускаем команду sudo , а затем — passwd. Таким образом мы сможем войти в систему, когда загрузимся.
Также нам очень понадобятся пара пакетов — GCC и любой текстовый редактор, например Vim. Они нужны для написания и компиляции эксплоита. Эти пакеты можно получить с помощью команд apt на Debian-системе или pacman для Arch-подобной ОС. Также желательно создать обычного пользователя, от имени которого мы будем проверять эксплоит. Для этого выполним команды useradd и passwd , чтобы у него была домашняя папка.
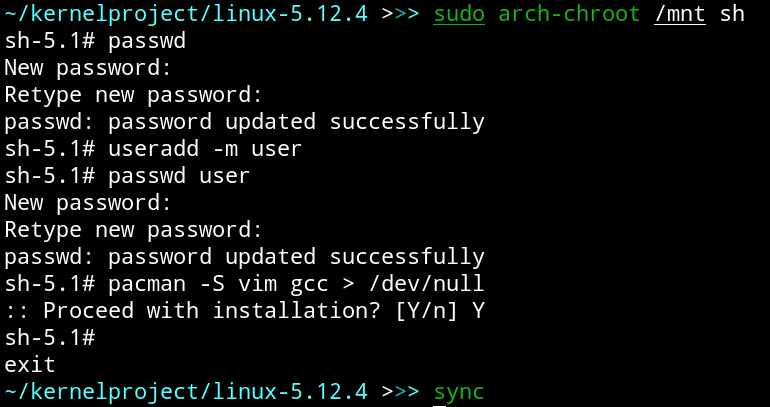
Выйдем из chroot с помощью Ctrl + d и на всякий случай напишем sync.
Финальные штрихи
На самом деле по‑хорошему надо отмонтировать rootfs. командой sudo . Лично я после записи в / всегда дополнительно делаю sync, чтобы записанные данные не потерялись в кеше. Теперь мы полностью готовы к запуску ядра с нашим модулем.
Запуск ядра
После сборки само ядро будет лежать в сжатом виде в <. Хоть оно и сжато, ядро спокойно запустится в QEMU, потому что это самораспаковывающийся бинарник.
При условии, что мы находимся в папке < и там же находится rootfs., команда для запуска ядра будет такой:
-kernel ./arch/x86/boot/bzImage
-append“console=ttyS0,115200 root=/dev/sda rw nokaslr”
-hda ./rootfs.img
-nographicВ kernel мы указали путь к ядру, append является командной строкой ядра, console=ttyS0, говорит о том, что вывод будет даваться в устройство ttyS0 со скоростью передачи данных 115 200 бит/с. Это просто serial-порт, откуда берет данные QEMU. Аргумент root=/ делает корневой файловой системой диск, который мы потом включили с помощью ключа hda, а rw делает эту файловую систему доступной для чтения и записи (по умолчанию только для чтения). Параметр nokaslr нужен, чтобы не рандомизировались адреса функций ядра в виртуальной памяти. Этот параметр упростит эксплуатацию. Наконец, -nographic выполняет запуск без отдельного окошка прямо в консоли.
После запуска мы можем залогиниться и попасть в консоль. Однако, если зайти в /, мы не найдем нашего устройства. Чтобы оно появилось, надо выполнить команду insmod /. Сообщения о загрузке добавятся в kmsg, а в / появится устройство vuln. Однако есть небольшая проблема: / имеет права 600. Для нашей эксплуатации необходимы права 666 или хотя бы 622, чтобы любой пользователь мог писать в этот файл. Мы можем вручную включать модуль в ядре, как и менять права устройству, но, согласись, выглядит это так себе. Просто представим, что это какой‑то важный модуль, который должен запускаться вместе с системой. Поэтому нам надо автоматизировать этот процесс.
Сервис для systemd
Автоматизировать процессы при загрузке можно разными способами: можно записать скрипт в /, можно поместить его в ~/., можно даже переписать init таким образом, чтобы сначала запускался наш скрипт, а потом вся остальная система. Однако легче всего написать модуль для systemd, программы, которая является непосредственно init и может автоматизировать разные вещи цивилизованным образом. Дальнейшие действия мы будем выполнять в системе, запущенной в QEMU. Она сохранит все изменения.
Непосредственно сервис
По факту нам надо сделать две вещи: вставить модуль в ядро и поменять права / на 666. Сервис запускается как скрипт — один раз во время загрузки системы. Поэтому тип сервиса будет oneshot. Давай посмотрим, что у нас получится.
[Unit]Name=Vulnerable module # Название модуля[Service]Type=oneshot # Тип модуля. Запустится один разExecStart=insmod /vuln.ko ; chmod 666 /dev/vuln # Команда для загрузки модуля и изменения разрешений[Install]WantedBy=multi-user.target # Когда модуль будет подгружен. Multi-user достаточно стандартная вещь для таких модулейЭтот код должен будет лежать в /.
Запуск сервиса
Так как скрипт должен запускаться во время загрузки системы, надо выполнить команду systemctl от имени суперпользователя.
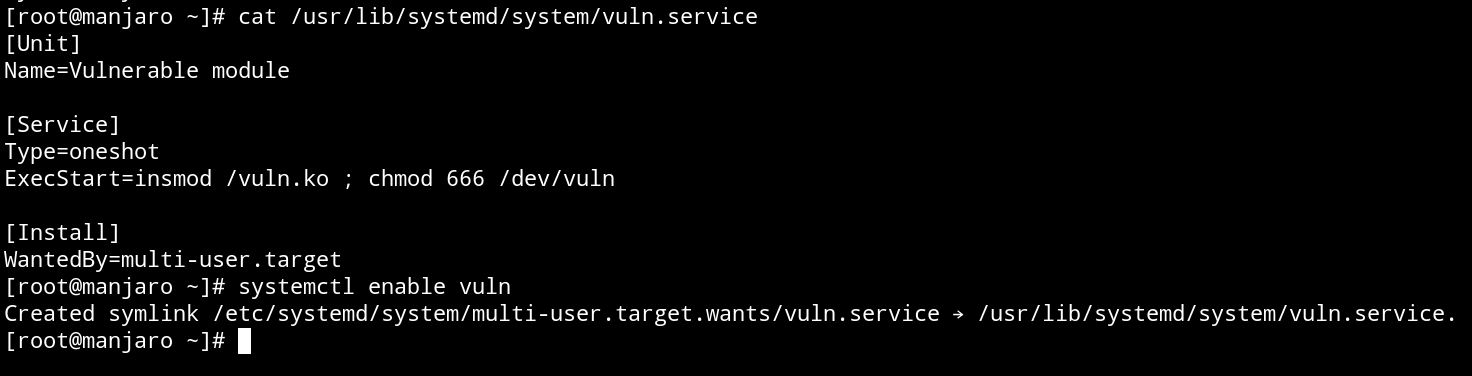
После перезагрузки файл vuln в / получит права rw-rw-rw-. Прекрасно. Теперь переходим к самому сладкому. Чтобы выйти из QEMU, нажми Ctrl + A, C и D.
Дебаггинг ядра
Дебажить ядро мы будем для того, чтобы посмотреть, как оно работает во время наших вызовов. Это позволит нам понять, как эксплуатировать уязвимость. Опытные читатели, скорее всего, знают о One gadget в libc, стандартной библиотеке C в Linux, позволяющей почти сразу запустить / из уязвимой программы в userspace. В ядре же кнопки «сделать классно» нет, но есть другая, посложнее.
GDB и vmlinux-gdb.py
Настоятельно рекомендую тебе использовать GEF для упрощения работы. Это модуль для GDB, который умеет показывать состояния регистров, стека и кода во время работы. Его можно взять здесь.
Первым делом надо разрешить загрузку сторонних скриптов, а именно vmlinux-gdb., который сейчас находится в корневой папке исходников. Как, собственно, и vmlinux, файл с символами ядра. Он поможет впоследствии узнать базовый адрес модуля ядра. Это можно сделать, добавив строку set в ~/.. Теперь, чтобы загрузить символы и вообще код, выполни команду gdb . После этого надо запустить само ядро.
Перейти обратно к новости