Распуши пингвина! Разбираем способы фаззинга ядра Linux - «Новости»
2-08-2021, 00:00. Автор: Давид
info
Статья написана редакцией «Хакера» по мотивам доклада «Фаззинг ядра Linux» Андрея Коновалова при участии докладчика и изложена от первого лица с его разрешения.
Когда я говорю об атаках на USB, многие сразу вспоминают Evil HID — одну из атак типа BadUSB. Это когда подключаемое устройство выглядит безобидно, как флешка, а на самом деле оказывается клавиатурой, которая автоматически открывает консоль и делает что‑нибудь нехорошее.
В рамках моей работы по фаззингу такие атаки меня не интересовали. Я искал в первую очередь повреждения памяти ядра. В случае атаки через USB сценарий похож на BadUSB: мы подключаем специальное USB-устройство и оно начинает делать нехорошие вещи. Но оно не набирает команды, прикидываясь клавиатурой, а эксплуатирует уязвимость в драйвере и получает исполнение кода внутри ядра.
За годы работы над фаззингом ядра у меня скопилась коллекция ссылок и наработок. Я их упорядочил и превратил в доклад. Сейчас я расскажу, какие есть способы фаззить ядро, и дам советы начинающим исследователям, которые решат заняться этой темой.
Что такое фаззинг
Фаззинг — это способ искать ошибки в программах.
Как он работает? Мы генерируем случайные данные, передаем их на вход программе и проверяем, не сломалась ли она. Если не сломалась — генерируем новый ввод. Если сломалась — прекрасно, мы нашли баг. Предполагается, что программа не должна падать от неожиданного ввода, она должна этот ввод корректно обрабатывать.
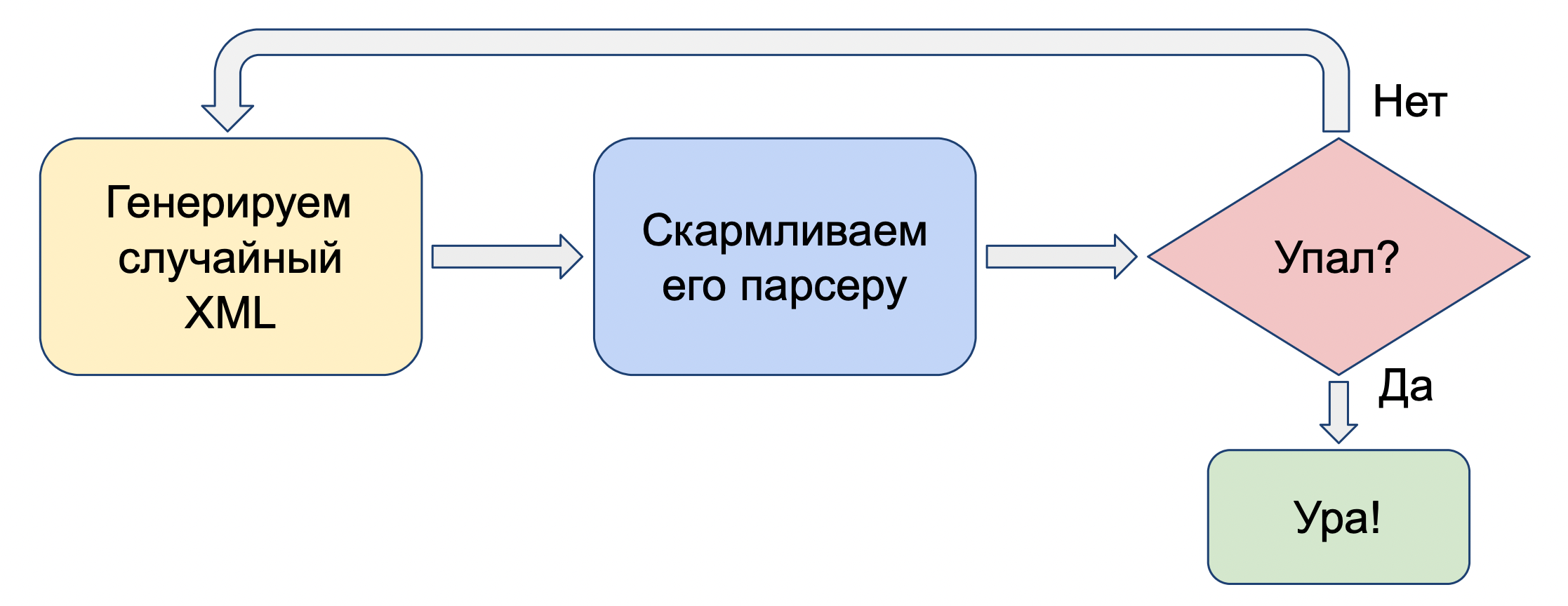
Конкретный пример: мы берем XML-парсер и скармливаем ему случайно сгенерированные XML-файлы. Если он упал — мы нашли баг в парсере.
Фаззеры можно делать для любой штуки, которая обрабатывает входные данные. Это может быть приложение или библиотека в пространстве пользователя — юзерспейсе. Это может быть ядро, может быть прошивка, а может быть даже железо.
Когда мы начинаем работать над фаззером для очередной программы, нам нужно разобраться со следующими вопросами:
Как программу запускать? В случае приложения в юзерспейсе — запустить бинарник. А вот запустить ядро или части прошивки так просто не выйдет.
Что служит входными данными? Для XML-парсера входные данные — XML-файлы. А, например, браузер и обрабатывает HTML, и исполняет jаvascript.
Как входные данные программе передавать? В простейшем случае данные передаются на стандартный ввод или в виде файла. Но программы могут получать данные и через другие каналы. Например, прошивка может получать их от физических устройств.
Как генерировать вводы? «Вводом» будем называть набор данных, переданный программе на вход. В качестве ввода можно создавать массивы рандомных байтов, а можно делать что‑нибудь более умное.
Как определять факт ошибки? Если программа упала — это баг. Но существуют ошибки, которые не приводят к падению. Пример: утечка информации. Такие ошибки тоже хочется находить.
Как автоматизировать процесс? Можно запускать программу с новыми вводами вручную и смотреть, не упала ли она. А можно написать скрипт, который будет делать это автоматически.
Сегодня мы говорим о ядре Linux, так что в каждом из вопросов мы можем мысленно заменить слово «программа» на «ядро Linux». А теперь давай попробуем найти ответы.
Простой способ
Для начала придумаем ответы попроще и разработаем первую версию нашего фаззера.
Запускаем ядро
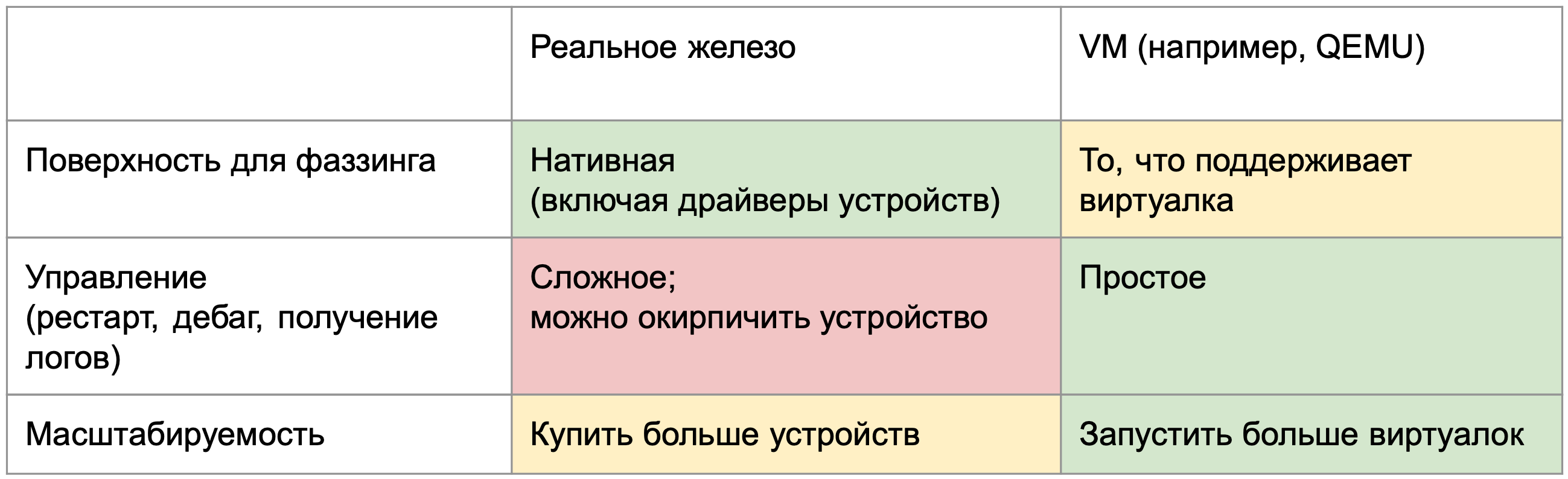
Начнем с того, как ядро запускать. Здесь есть два способа: использовать железо (компьютеры, телефоны или одноплатники) или использовать виртуальные машины (например, QEMU). У каждого свои плюсы и минусы.
Когда запускаешь ядро на железе, то получаешь систему в том виде, в котором она работает в реальности. Например, там доступны и работают драйверы устройств. В виртуалке доступны только те фичи, которые она поддерживает.
С другой стороны, железом гораздо сложнее управлять: разливать ядра, перезагружать в случае падения, собирать логи. Виртуалка в этом плане идеальна.
Еще один плюс виртуальных машин — масштабируемость. Чтобы фаззить на большем количестве железок, их надо купить, что может быть дорого или логистически сложно. Для масштабирования фаззинга в виртуалках достаточно взять машину помощнее и запустить их сколько нужно.
Учитывая особенности каждого из способов, виртуалки выглядят как лучший вариант. Но давай для начала ответим на остальные вопросы. Глядишь, мы придумаем способ фаззить, который не привязан к способу запуска ядра.
Разбираемся со вводами
Что является входными данными для ядра? Ядро обрабатывает системные вызовы — сисколы (syscall). Как передать их в ядро? Давай напишем программу, которая делает последовательность вызовов, скомпилируем ее в бинарь и запустим. Всё: ядро будет интерпретировать наши вызовы.
Теперь разберемся с тем, какие данные передавать в сисколы в качестве аргументов и в каком порядке сисколы вызывать.
Самый простой способ генерировать данные — брать случайные байты. Этот способ работает плохо: обычно программы, включая то же ядро, ожидают данные в более‑менее корректном виде. Если передать им совсем мусор, даже элементарные проверки на корректность не пройдут, и программа откажется обрабатывать ввод дальше.
Способ лучше: генерировать данные на основе грамматики. На примере XML-парсера: мы можем заложить в грамматику знание о том, что XML-файл состоит из XML-тегов. Таким образом мы обойдем элементарные проверки и проникнем глубже внутрь кода парсера.
Однако для ядра такой подход надо адаптировать: ядро принимает последовательность сисколов с аргументами, а это не просто массив байтов, даже сгенерированных по определенной грамматике.
Представь программу из трех сисколов: open, который открывает файл, ioctl, который совершает операцию над этим файлом, и close, который файл закрывает. Для open первый аргумент — это строка, то есть простая структура с единственным фиксированным полем. Для ioctl, в свою очередь, первый аргумент — значение, которое вернул open, а третий — сложная структура с несколькими полями. Наконец, в close передается все тот же результат open.
int fd = open("/dev/something", …);ioctl(fd,SOME_IOCTL, &{0x10, ...});close(fd);Целиком эта программа — типичный ввод, который обрабатывает ядро. То есть вводы для ядра представляют собой последовательности сисколов. Причем их аргументы структурированы, а их результат может передаваться от одного сискола к другому.
Это все похоже на API некой библиотеки — его вызовы принимают структурированные аргументы и возвращают результаты, которые могут передаваться в следующие вызовы.
Получается, что, когда мы фаззим сисколы, мы фаззим API, который предоставляет ядро. Я такой подход называю API-aware-фаззинг.
В случае ядра Linux, к сожалению, точного описания всех возможных сисколов и их аргументов нет. Есть несколько попыток сгенерировать эти описания автоматически, но ни одна из них не выглядит удовлетворительной. Поэтому единственный способ — это написать описания руками.
Так и сделаем: выберем несколько сисколов и разработаем алгоритм генерирования их последовательностей. Например, заложим в него, что в ioctl должен передаваться результат open и структура правильного типа со случайными полями.
[Не] автоматизируем
С автоматизацией пока не будем заморачиваться: наш фаззер в цикле будет генерировать вводы и передавать их ядру. А мы будем вручную мониторить лог ядра на предмет ошибок типа kernel panic.
Готово
Всё! Мы ответили на все вопросы и разработали простой способ фаззинга ядра.
| Как запускать ядро? | В QEMU или на реальном железе |
| Что будет входными данными? | Системные вызовы |
| Как входные данные передавать ядру? | Через запуск исполняемого файла |
| Как генерировать вводы? | На основе API ядра |
| Как определять наличие багов? | По kernel panic |
| Как автоматизировать? | while ( |
Наш фаззер представляет собой бинарник, который в случайном порядке вызывает сисколы с более‑менее корректными аргументами. Поскольку бинарник можно запустить и на виртуалке, и на железе, то фаззер получился универсальным.
Ход рассуждений был простым, но сам подход работает прекрасно. Если специалиста по фаззингу ядра Linux спросить: «Какой фаззер работает описанным способом?», то он сразу скажет: Trinity! Да, фаззер с таким алгоритмом работы уже существует. Одно из его преимуществ — он легко переносимый. Закинул бинарь в систему, запустил — и все, ты уже ищешь баги в ядре.
Способ получше
Фаззер Trinity сделали давно, и с тех пор мысль в области фаззинга ушла дальше. Давай попробуем улучшить придуманный способ, использовав более современные идеи.
Собираем покрытие
Идея первая: для генерации вводов использовать подход coverage-guided — на основе сборки покрытия кода.
Как он работает? Помимо генерирования случайных вводов с нуля, мы поддерживаем набор ранее сгенерированных «интересных» вводов — корпус. И иногда, вместо случайного ввода, мы берем один ввод из корпуса и его слегка модифицируем. После чего мы исполняем программу с новым вводом и проверяем, интересен ли он. А интересен ввод в том случае, если он позволяет покрыть участок кода, который ни один из предыдущих исполненных вводов не покрывает. Если новый ввод позволил пройти дальше вглубь программы, то мы добавляем его в корпус. Таким образом, мы постепенно проникаем все глубже и глубже, а в корпусе собираются все более и более интересные программы.
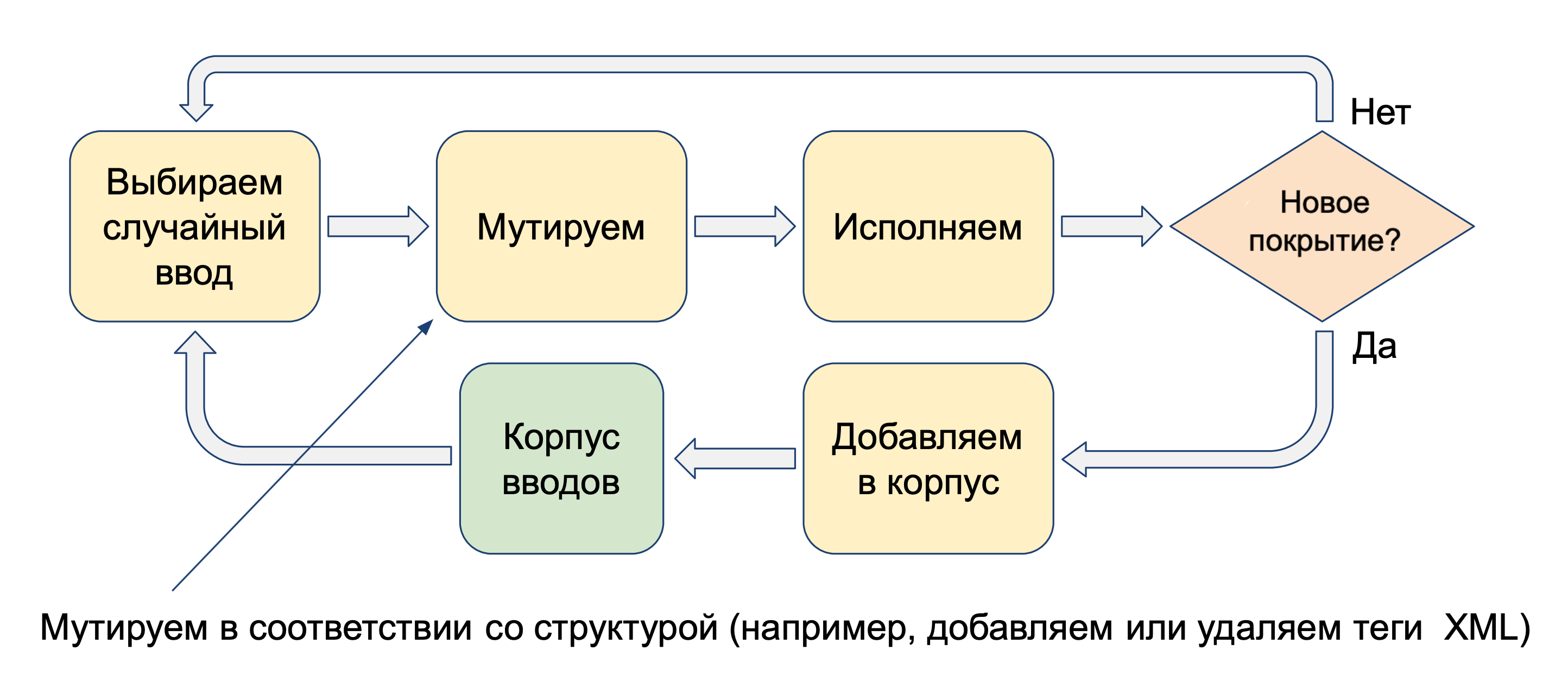
Этот подход используется в двух основных инструментах для фаззинга приложений в юзерспейсе: AFL и libFuzzer.
Перейти обратно к новости