Учебник CSS
Невозможно отучить людей изучать самые ненужные предметы.
Введение в CSS
Преимущества стилей
Добавления стилей
Типы носителей
Базовый синтаксис
Значения стилевых свойств
Селекторы тегов
Классы
CSS3
Надо знать обо всем понемножку, но все о немногом.
Идентификаторы
Контекстные селекторы
Соседние селекторы
Дочерние селекторы
Селекторы атрибутов
Универсальный селектор
Псевдоклассы
Псевдоэлементы
Кто умеет, тот делает. Кто не умеет, тот учит. Кто не умеет учить - становится деканом. (Т. Мартин)
Группирование
Наследование
Каскадирование
Валидация
Идентификаторы и классы
Написание эффективного кода
Самоучитель CSS
Вёрстка
Изображения
Текст
Цвет
Линии и рамки
Углы
Списки
Ссылки
Дизайны сайтов
Формы
Таблицы
CSS3
HTML5
Новости
Блог для вебмастеров
Новости мира Интернет
Сайтостроение
Ремонт и советы
Все новости
Справочник CSS
Справочник от А до Я
HTML, CSS, JavaScript
Афоризмы
Афоризмы о учёбе
Статьи об афоризмах
Все Афоризмы

- 18 декабря 2025, 07:17

| Помогли мы вам |


- 18 декабря 2025, 07:17

- 09 декабря 2025, 15:14
ИИ в ИБ. Как машинное обучение применяется в безопасности и каким оно бывает - «Новости»
Хакердом» за помощь в подготовке статьи.
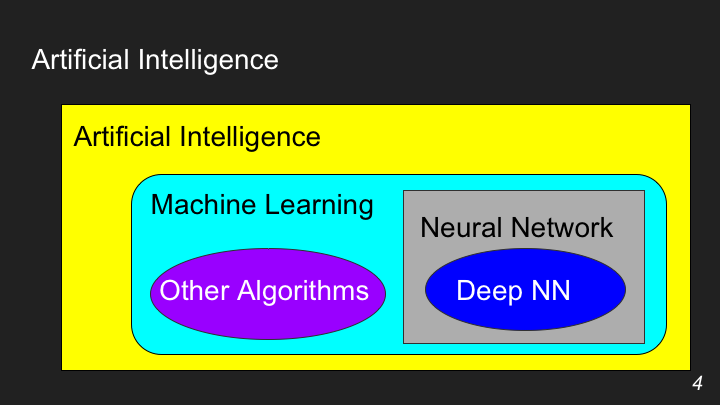
Искусственный интеллект — это на самом деле сразу несколько областей компьютерных наук, которые решают задачи, свойственные человеческому разуму: распознавание речи, классификация объектов, а также разные игры вроде шахмат и го.
Машинное обучение — это часть темы искусственного интеллекта, где изучается не прямое программирование задач, а программирование через обучение в процессе решения однотипных задач.
В понятие машинлернинга входят разные алгоритмы — такие как random forest («случайный лес»), деревья решений, наивный байесовский классификатор, градиентный бустинг и другие. Нейронные сети, в том числе глубокие, — это тоже один из алгоритмов машинного обучения.
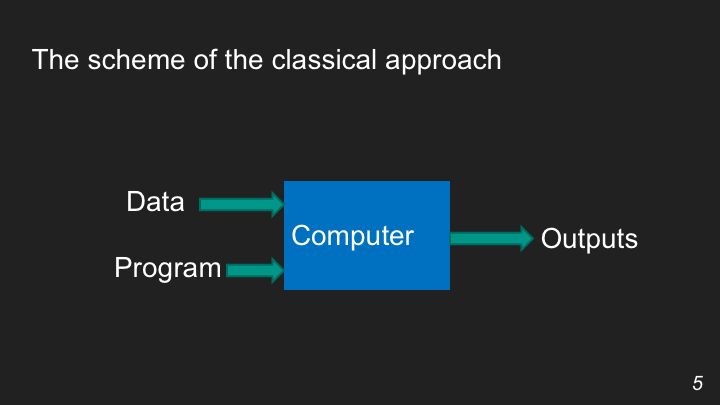
Классический кодинг vs машинное обучение
Как происходит программирование в классическом понимании? Допустим, у человека есть компьютер, который работает по определенному алгоритму. Человек вводит в него данные, подает программу, и алгоритм выдает результаты. В этом случае все предельно понятно. Человек может получить точность до 100 процентов, особенно если запрос — это математические операции.
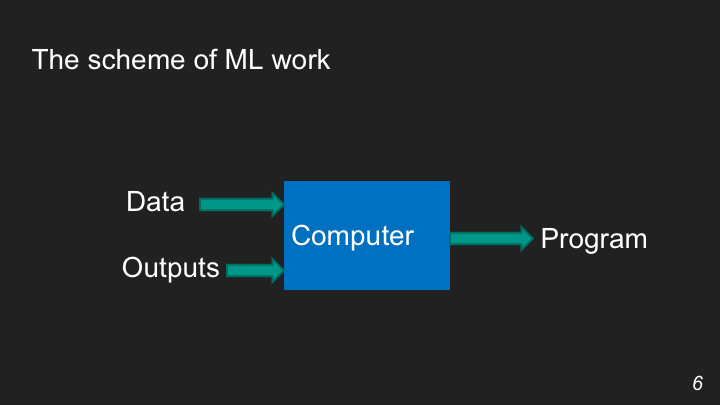
А вот в случае с машинным обучением программа и выходы поменяются местами. То есть человек дает алгоритму данные и указывает правильные решения, а дальше компьютер думает, как сделать так, чтобы из этих данных получались желаемые результаты. В процессе такой работы и рождается программа.
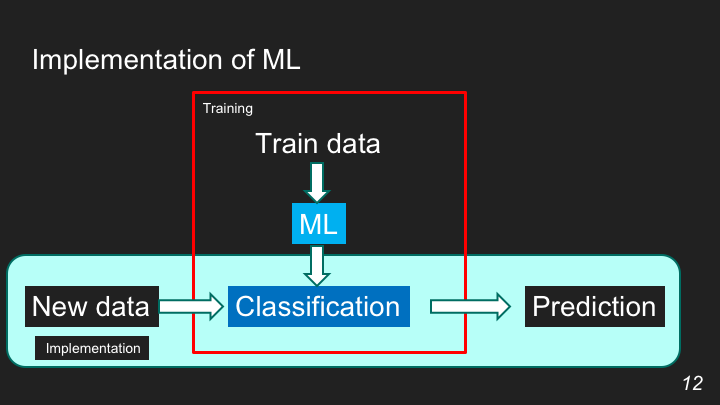
Задачи искусственного интеллекта
Есть четыре основные задачи искусственного интеллекта:
- классификация;
- регрессия;
- ранжирование;
- кластеризация.
Машинное обучение состоит из двух процессов. Первый — это тренировка, когда человек берет данные, обучает модель и в итоге получает некий классификатор.

Второй процесс — это уже использование ML, когда обученный классификатор внедряется в систему, а затем на вход системы подают новые данные, которые классификатор не видел. В результате мы получаем предсказания от классификатора.
Чем машинлернинг может помочь в ИБ
Рассмотрим пример того, как человек пользуется своей электронной почтой. Можно выделить четыре паттерна поведения человека, анализ которых поможет определить его действия.
- В какое время суток человек пользуется почтой: утром, днем, вечером.
- Сколько устройств использует: телефон, компьютер или сразу несколько устройств одновременно.
- В каких локациях человек находится, когда пользуется почтой.
- Как человек проверяет письма: сверху вниз или снизу вверх. Мы можем определить это по тому, как он отвечает или удаляет из ящика рассылки и прочий мусор.
Ответы на эти вопросы создает портрет человека (на рисунке ниже поведение такого человека выделено красным). Для машинного обучения эти действия будут предсказуемые, без каких‑либо всплесков.
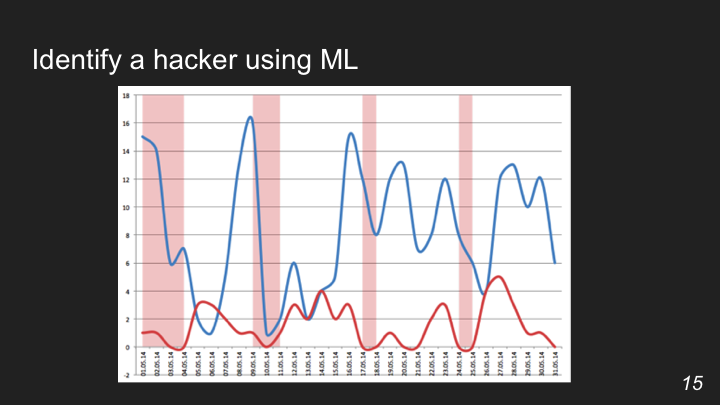
Теперь представим, что хакер взломал почту, узнав каким‑то образом пароль от нее, и зашел как пользователь. Его поведение будет явно отличаться от поведения человека, который пользовался электронным ящиком до него. На графике поведение хакера показано характерными всплесками.
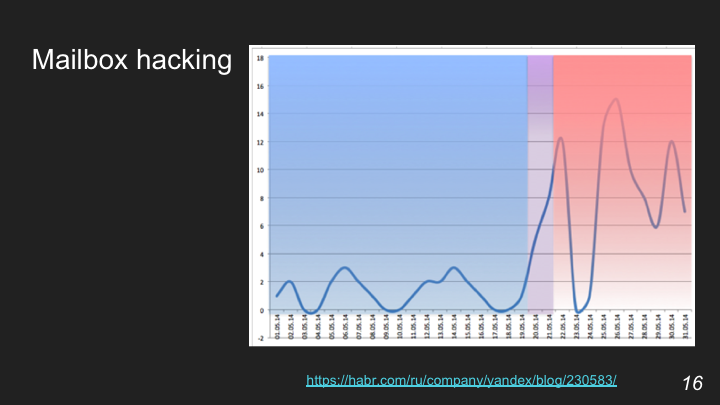
Задача алгоритма заключается в том, чтобы определить тот момент, когда изменилось поведение человека, которое образовало такой всплеск. О подобном примере можешь почитать в блоге Яндекса на Хабре.
Другой хороший пример — соревнования Catch me if you can на сайте Kaggle. Это, кстати, очень полезный сайт для тех, кто хочет изучить машинное обучение.
Задача — отличить поведение взломщика от нормального пользователя. Например, дано: сайты, которые посещает человек, и время нахождения человека на них. Нужно по последовательности посещений сайтов определить взломщика. На стартовой странице представлен обзор задачи и размеченные данные. А также есть вкладка, где можно найти, как эту задачу решили другие пользователи. То есть Kaggle дает возможность не только поучаствовать в соревнованиях, но и набраться опыта у других людей.
Что включает в себя машинное обучение
Машинное обучение включает в себя три компонента: данные, признаки и алгоритмы. Давай рассмотрим их по отдельности.
Данные
В открытом доступе есть множество наборов данных, на которых можно тренировать алгоритмы. Но у таких наборов есть недостатки. Например, наборы могут быть неполными, плохо размечены и неточны. Если ты захочешь внедрить решение на ML-технологиях, нужно будет собрать набор данных под определенную задачу и готовый набор вряд ли будет хорошо соответствовать. Люди готовы выкладывать алгоритмы, рассказывать, что и как они используют, но мало кто хочет делиться своими наборами данных.
Задача дата‑сайентиста — подготовить набор данных к использованию: собрать, разметить и вычистить его. Это очень трудоемкий процесс, который занимает примерно 50–70 процентов работы.
Признаки
Рассмотрим простой веб‑запрос. Допустим, у тебя есть: длина запроса, код ответа, URL, контекст, популярность домена и так далее. Всего таких признаков можно набрать 600 штук. В этом случае возникает два важных вопроса:
- Какие из этих признаков брать, а какие не стоит?
- Где будет использовано решение — в режиме realtime или офлайн?
Причем тебе придется искать компромисс между этими двумя параметрами. Например, если решение будет использовано в реальном времени, нужно, чтобы модель могла быстро считать. Поэтому признаков стоит взять поменьше, модельку послабее. В офлайновом режиме можно выгрузить данные, анализировать их и раскидывать по категориям. В этом случае используй любую модель любой сложности, потому что можно заставить алгоритм думать столько, сколько понадобится.
Вот еще один пример. Предположим, нам нужно понять, опасный перед нами файл или нет. Для этого сначала ответим на следующие вопросы:
- Требует ли файл доступ в интернет?
- Делает ли он что‑то похожее на сканирование?
- Какие IP использует файл?
- Хочет ли он достучаться до реестра?
- Работает ли файл с памятью?
- Хочет ли он изменить файловую систему?
- Имеет ли файл возможность самокопирования или захвата других файлов?
Ответы на эти вопросы помогут выявить признаки, которые можно использовать для решения нашей задачи.
Алгоритмы
Алгоритмы можно разделить на несколько типов:
- обучение без учителя;
- обучение с учителем;
- обучение с частичным привлечением учителя (semi-supervised learning);
- обучение с подкреплением.
- © Постквантовый VPN. Разбираемся с квантовыми компьютерами и ставим OpenVPN с защитой от будущих угроз - «Новости»
- © Безопасность памяти. Учимся использовать указатели и линейные типы - «Новости»
- © YOLO! Используем нейросеть, чтобы следить за людьми и разгадывать капчу - «Новости»
- © Не App Store единым. Устанавливаем сторонние приложения в iOS без джейла - «Новости»
- © Сборка мусора. Разбираем мифы об автоматическом управлении памятью - «Новости»
- © Малварь на просвет. Используем Python для динамического анализа вредоносного кода - «Новости»
- © Реверсинг .NET. Как искать JIT-компилятор в приложениях - «Новости»
- © Погружение в ассемблер. Сокращаем размер программы - «Новости»
- © Погружение в ассемблер. Зачем учить ассемблер в 2020 году - «Новости»
- © Разгребаем руины. Как восстановить удаленные файлы на разделах NTFS - «Новости»
|
|
|
|
АВТОРИЗАЦИЯ
|
• Мы информационный портал, на котором публикуются новости веб-дизайна и мелкие хитрости, а так же информация и советы которые вам смогут помочь по созданию сайтов, шаблонов, и многое другое. Вы также сможете найти интересные уроки по CSS3, HTML5, jQuery, Photoshop и и многое другое, интересное, с интернет мира. Вся информация размещенная на сайте предназначена исключительно в ознакомительных целях и ошибки в учении не кто не отменял .. Как говориться - "Не бойся, когда не знаешь: страшно, когда знать не хочется." «Самоучитель CSS » → © Мы транслируем с 2006 года. Все для веб-дизайнера - CSS. Все материалы публикуют на сайте гости и пользователи сайта. Администрация сайта не несет ответственности за публикации. |

|