Учебник CSS
Невозможно отучить людей изучать самые ненужные предметы.
Введение в CSS
Преимущества стилей
Добавления стилей
Типы носителей
Базовый синтаксис
Значения стилевых свойств
Селекторы тегов
Классы
CSS3
Надо знать обо всем понемножку, но все о немногом.
Идентификаторы
Контекстные селекторы
Соседние селекторы
Дочерние селекторы
Селекторы атрибутов
Универсальный селектор
Псевдоклассы
Псевдоэлементы
Кто умеет, тот делает. Кто не умеет, тот учит. Кто не умеет учить - становится деканом. (Т. Мартин)
Группирование
Наследование
Каскадирование
Валидация
Идентификаторы и классы
Написание эффективного кода
Самоучитель CSS
Вёрстка
Изображения
Текст
Цвет
Линии и рамки
Углы
Списки
Ссылки
Дизайны сайтов
Формы
Таблицы
CSS3
HTML5
Новости
Блог для вебмастеров
Новости мира Интернет
Сайтостроение
Ремонт и советы
Все новости
Справочник CSS
Справочник от А до Я
HTML, CSS, JavaScript
Афоризмы
Афоризмы о учёбе
Статьи об афоризмах
Все Афоризмы

- 18 декабря 2025, 07:17

| Помогли мы вам |


- 18 декабря 2025, 07:17

- 09 декабря 2025, 15:14
Фундаментальные основы хакерства. Ищем тестовые строки в чужой программе - «Новости»
странице автора.
Казалось бы, что может быть сложного в идентификации строк? Если то, на что ссылается указатель, выглядит как строка, это и есть строка! Более того, в подавляющем большинстве случаев строки обнаруживаются и идентифицируются тривиальным просмотром дампа программы (при условии, конечно, что они не зашифрованы, но шифрование — тема отдельного разговора). Так‑то оно так, да не все столь просто!
Задача номер один — автоматизированное выявление строк в программе: не пролистывать же мегабайтовые дампы вручную? Существует множество алгоритмов идентификации строк. Самый простой (но не самый надежный) основан на двух тезисах:
- строка состоит из ограниченного ассортимента символов. В грубом приближении — это цифры, буквы алфавита (включая пробелы), знаки препинания и служебные символы наподобие табуляции или возврата каретки;
- строка должна состоять по крайней мере из нескольких символов.
Условимся считать минимальную длину строки равной N байтам. Тогда для автоматического выявления всех строк достаточно отыскать все последовательности из N и более «строковых» символов. Весь вопрос в том, чему должна быть равна N и какие символы считать «строковыми».
Если N имеет малое значение, порядка трех‑четырех байтов, то мы получим очень большое количество ложных срабатываний. Напротив, когда N велико, порядка шести‑восьми байтов, число ложных срабатываний близко к нулю и ими можно пренебречь, но все короткие строки, например OK, YES, NO, окажутся не распознаны! Другая проблема: помимо знако‑цифровых символов, в строках встречаются и элементы псевдографики (особенно часты они в консольных приложениях) и всякие там «мордашки», «стрелки», «карапузики» — словом, почти вся таблица ASCII. Чем же тогда строка отличается от случайной последовательности байтов? Частотный анализ здесь бессилен: ему для нормальной работы требуется как минимум сотня байтов текста, а мы говорим о строках из двух‑трех символов!
Зайдем с другого конца. Если в программе есть строка, значит, на нее кто‑нибудь да ссылается. А раз так, можно поискать среди непосредственных значений указатель на распознанную строку. И если он будет найден, шансы на то, что это действительно именно строка, а не случайная последовательность байтов, резко возрастают. Все просто, не так ли?
Просто, да не совсем! Рассмотрим следующий пример (writeln_d):
program writeln_d;begin Writeln('Hello, Sailor!');end.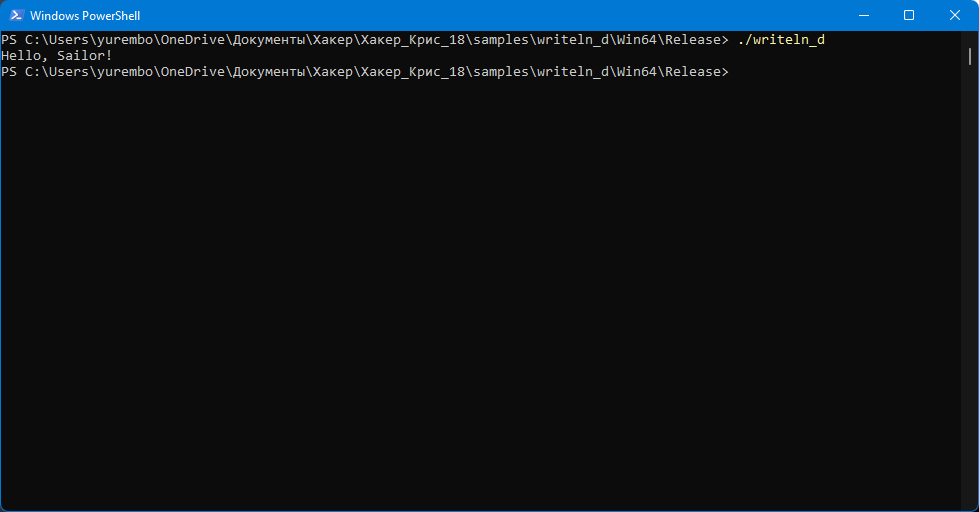
Результат выполнения writeln_d
Откомпилируем этот пример. Хотелось бы сказать, любым Pascal-компилятором, только любой нам не подойдет, поскольку нам нужен бинарный код под архитектуру x86-64. Это автоматически сужает круг подходящих компиляторов. Даже популярный Free Pascal все еще не умеет билдить программы для Windows x64. Но не убирай его далеко, он нам еще пригодится.
В таком случае нам придется воспользоваться Embarcadero Delphi 10.4. Настрой компилятор для построения 64-битных приложений и загрузи откомпилированный файл в дизассемблер:
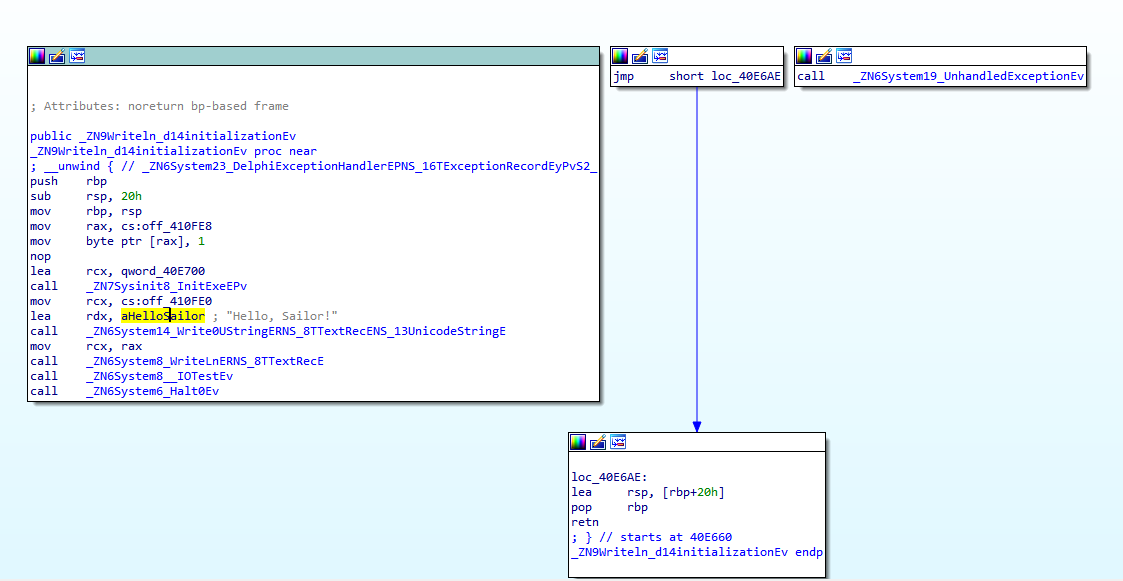
IDA определила, что перед вызовом функции _ZN6System14_Write0UStringERNS_8TTextRecENS_13UnicodeStringE в регистр RDX загружается указатель на смещение aHelloSailor. Посмотрим, куда оно указывает (дважды щелкнем по нему):
.text:000000000040E6DC aHelloSailor: ; DATA XREF: _ZN9Writeln_d14initializationEv+26↑o.text:000000000040E6DC text "UTF-16LE", 'Hello, Sailor!',0Ага! Текст в кодировке UTF-16LE. Что такое UTF-16, думаю, всем понятно. Два конечных символа обозначают порядок байтов. В данном случае, поскольку приложение скомпилировано для архитектуры x86-64, в которой используется порядок байтов «от младшего к старшему» — little endian, упомянутые символы говорят именно об этом. В противоположном случае, например на компьютере с процессором SPARC, кодировка имела бы название UTF-16BE от big endian.
Из этого следует, что Delphi кодирует каждый символ переменным количеством байтов: 2 или 4. Посмотрим, как себя поведет Visual C++ 2019 с аналогичным кодом:
#include <stdio.h>int main() { printf("%s", "Hello, Sailor!");}Результат дизассемблирования:
main proc near sub rsp, 28h lea rdx, aHelloSailor ; "Hello, Sailor!" lea rcx, _Format; "%s" call printf xor eax, eax add rsp, 28h retnmain endpПоинтересуемся, что находится в сегменте данных только для чтения (rdata) по смещению aHelloSailor:
.rdаta:0000000140002240 aHelloSailor db 'Hello, Sailor!',0 ; DATA XREF: main+4↑oНикаких дополнительных сведений о размере символов. Из этого можно сделать вывод, что используется стандартная 8-битная кодировка ASCII, в которой под каждый символ отводится только 1 байт.
Ядро Windows NT изначально использовало для работы со строковыми символами кодировку UTF-16, однако до Windows 10 в пользовательском режиме применялись две кодировки: UTF-16 и ASCII (нижние 128 символов для английского языка, верхняя половина — для русского). Начиная с Windows 10, в user mode используется только UTF-16. Между тем символы могут храниться и в ASCII, что мы видели в примере выше.
В C/C++ char является исходным типом символа и позволяет хранить любой символ нижней и верхней частей кодировки ASCII размером 8 бит. Хотя реализация типа wchar_t полностью лежит на совести разработчика компилятора, в Visual C++ он представляет собой полный аналог символа кодировки UTF-16LE, то есть позволяет хранить любой символ Юникода.
Для демонстрации двух основных символьных типов в Visual C++ напишем элементарный пример:
int main() { std::cout << "size of 'char': " << sizeof(char) << "n"; std::cout << "size of 'wchar': " << sizeof(wchar_t) << "n"; char line1[] = "Hello, Sailor!"; wchar_t line2[] = L"Hello, Sailor!"; std::cout << "size of 'array of chars': " << sizeof(line1) << "n"; std::cout << "size of 'array of wchars': " << sizeof(line2) << "n";}
Результат его выполнения представлен ниже.
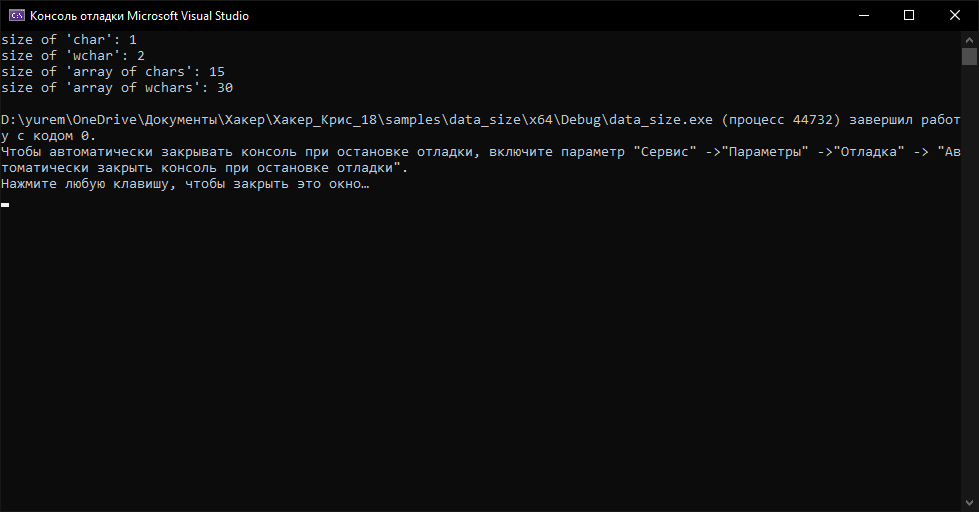
Размеры символьных данных
Думаю, все понятно без подробных пояснений: char — 1 байт, wchar_t — 2 байта. Строка "Hello, Sailor!" состоит из 14 символов, плюс конечный 0. Это также отражено в выводе программы.
info
В стандарте C++ есть типы символов: char8_t, char16_t, char32_t. Первый из них был добавлен с введением стандарта C++20, два других добавлены в C++11. Их размер отражается в их названиях: char16_t используется для символов кодировки UTF-16, char32_t — для UTF-32. При этом char8_t не то же самое, что «унаследованный» char, хотя позволяет работать с символами последнего, главным образом он предназначен для литералов кодировки UTF-8.
Размеры символов важны для обнаружения границ строк при анализе дизассемблерных листингов программ.
Можно сделать вывод, что современные Visual C++ и Delphi оперируют одинаковыми типами строк, неважно какого размера, но оканчивающиеся символом 0. Но так было не всегда. В качестве исторического экскурса откомпилируем пример writeln_d компилятором Free Pascal.

Среда Free Pascal
Загрузим результат в IDA.
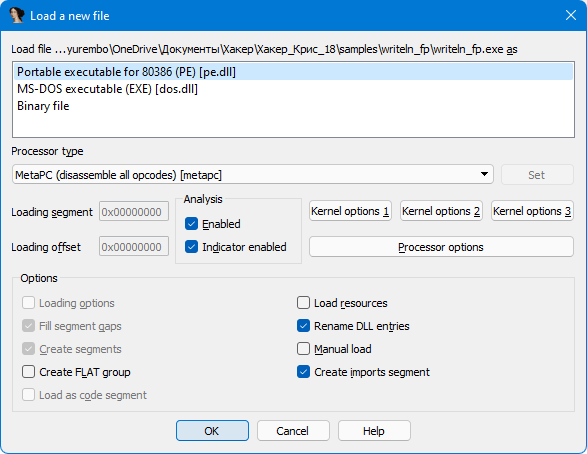
IDA определила, что загружаемый исполняемый файл 32-разрядныйargc = dword ptr 8argv = dword ptr 0Chenvp = dword ptr 10hpush
ebpmov
ebp, esppush
ebxcall
FPC_INITIALIZEUNITScall
fpc_get_outputmov
ebx, eaxmov
ecx, offset _$WRITELN_FP$_Ld1mov
edx, ebxmov
eax, 0call
FPC_WRITE_TEXT_SHORTSTRcall
FPC_IOCHECKmov
eax, ebxcall
fpc_writeln_endcall
FPC_IOCHECKcall
FPC_DO_EXIT_main endp
Так‑так‑так… какой интересный код для нас приготовил Free Pascal! Сразу же бросается в глаза смещение
адрес которого помещается в регистр ECX перед вызовом процедуры FPC_WRITE_TEXT_SHORTSTR, своим названием намекающей на вывод текста. Постой, ведь это же 32-разрядная программа, где передача параметров в регистрах скорее исключение, чем правило, и используется только при соглашении fastcall, в остальных же случаях параметры передаются через стек!
Заглянем‑ка в документацию по компилятору… Есть контакт! По умолчанию в коде механизма вызова процедур для процессоров i386 используется соглашение register. У нормальных людей оно называется fastcall. И, поскольку для платформы x86 оно не стандартизировано, в отличие от x64, для передачи параметров используются все свободные регистры! Поэтому в том, что используется регистр ECX, нет ничего сверхъестественного.
Чтобы окончательно убедиться в нашей догадке, посмотрим, как распоряжается переданным параметром вызываемая функция FPC_WRITE_TEXT_SHORTSTR:
FPC_WRITE_TEXT_SHORTSTR proc near ; CODE XREF: _main+1C↑p ; sub_403320+31↑p ... push ebx push esi push edi mov ebx, eax mov esi, edx mov edi, ecx ; Копирование параметра в регистр EDIНо тут много чего копируется, поэтому эта инструкция не доказательство. Смотрим дальше.
test
edx, edx
jzshort loc_40661C
mov
eax, ds:U_$SYSTEM_$$_INOUTRES
call
edx ; FPC_THREADVAR_RELOCATE
jmp
short loc_406621; ---------------------------------------------------------------------------loc_40661C: ; CODE XREF: FPC_WRITE_TEXT_SHORTSTR+11↑j
mov
eax, offset unk_40B154loc_406621: ; CODE XREF: FPC_WRITE_TEXT_SHORTSTR+1A↑j
cmp
word ptr [eax], 0
jnz
loc_4066AC
mov
eax, [esi+4]
cmp
eax, 0D7B1h
jlshort loc_40668C
sub
eax, 0D7B1h
jzshort loc_40666C
sub
eax, 1
jnz
short loc_40668C
mov
esi, esi
Ага! Следующая инструкция копирует указатель, преобразуя его в 32-разрядное значение без учета знака (указатель не может быть отрицательным). Затем с помощью команды cmp сравниваются значения двух регистров: EAX и EBX. И если EAX больше или равен EBX, выполняется переход на метку loc_40665C...
movzx eax, byte ptr [edi] cmp eax, ebx jge short loc_40665C movzx eax, byte ptr [edi] mov edx, ebx sub edx, eax mov eax, esi call sub_4064F0 lea esi, [esi+0]loc_40665C: ; CODE XREF: FPC_WRITE_TEXT_SHORTSTR+49↑j...где происходит похожая на манипуляцию со строкой деятельность.
movzx ecx, byte ptr [edi] lea edx, [edi+1] mov eax, esi call sub_406460 ...Теперь мы смогли убедиться в правильности нашего предположения! Вернемся к основному исследованию и посмотрим, что же скрывается под подозрительным смещением:
.rdаta:00409005 db 48h ; H.rdаta:00409006 db 65h ; e.rdаta:00409007 db 6Ch ; l.rdаta:00409008 db 6Ch ; l.rdаta:00409009 db 6Fh ; o.rdаta:0040900A db 2Ch ; ,.rdаta:0040900B db 20h.rdаta:0040900C db 53h ; S.rdаta:0040900D db 61h ; a.rdаta:0040900E db 69h ; i.rdаta:0040900F db 6Ch ; l.rdаta:00409010 db 6Fh ; o.rdаta:00409011 db 72h ; r.rdаta:00409012 db 21h ; !.rdаta:00409013 db
0
Согласись, не это мы ожидали увидеть. Однако последовательное расположение символов строки «в столбик» дела не меняет. Интересен другой момент: в начале строки стоит число, показывающее количество символов в строке, — 0xE (14 в десятичной системе).
Оказывается, мало идентифицировать строку, требуется еще как минимум определить ее границы.
Типы строк
Наиболее популярны следующие типы строк: С‑строки, которые завершаются нулем; DOS-строки, завершаются символом $ (такие строки используются не только в MS-DOS); Pascal-строки, которые предваряет одно-, двух- или четырехбайтовое поле, содержащее длину строки. Рассмотрим каждый из этих типов подробнее.
С-строки
С‑строки, также именуемые ASCIIZ-строками (от Zero — ноль на конце) или нуль‑терминированными, — весьма распространенный тип строк, широко использующийся в операционных системах семейств Windows и UNIX. Символ 0 (не путать с 0) имеет специальное предназначение и трактуется по‑особому, как признак завершения строки. Длина ASCIIZ-строк практически ничем не ограничена, ну разве что размером адресного пространства, выделенного процессу. Поэтому теоретически в Windows NT х64 максимальный размер ASCIIZ-строки лишь немногим менее 16 Тбайт.
Фактическая длина ASCIIZ-строк лишь на байт длиннее исходной ASCII-строки. Несмотря на перечисленные выше достоинства, С‑строкам присущи и некоторые недостатки. Во‑первых, ASCIIZ-строка не может содержать нулевых байтов, поэтому она непригодна для обработки бинарных данных. Во‑вторых, операции копирования, сравнения и конкатенации С‑строк сопряжены со значительными накладными расходами — современным процессорам невыгодно работать с отдельными байтами, им желательно иметь дело с четверными словами.
Но, увы, длина ASCIIZ-строк наперед неизвестна, и ее приходится вычислять на лету, проверяя каждый байт на символ завершения. Правда, разработчики некоторых компиляторов идут на хитрость: они завершают строку семью нулями, что позволяет работать с двойными словами, а это на порядок быстрее. Почему семью, а не четырьмя, ведь в двойном слове байтов четыре? Да, верно, четыре, но подумай, что произойдет, если последний значимый символ строки придется на первый байт двойного слова? Верно, его конец заполнят три нулевых байта, но двойное слово из‑за вмешательства первого символа уже не будет равно нулю! Вот поэтому следующему двойному слову надо предоставить еще четыре нулевых байта, тогда оно гарантированно будет равно нулю. Впрочем, семь служебных байтов на каждую строку — это уже перебор!
DOS-строки
В MS-DOS (и не только в ней) функция вывода строки воспринимает знак $ как символ завершения, поэтому в программистских кулуарах такие строки называют DOS-строками. Термин не совсем корректен: все остальные функции MS-DOS работают исключительно с ASCIIZ-строками!
- © Дробью в PDF. Редактируем подписанный файл PDF, не ломая подписи - «Новости»
- © Вскрытие покажет. Анализируем малварь в собственной лаборатории - «Новости»
- © Шаг за шагом. Автоматизируем многоходовые атаки в Burp Suite - «Новости»
- © Фундаментальные основы хакерства. Учимся идентифицировать аргументы функций - «Новости»
- © LUKS, eCryptFS или шифрование ZFS? Выбираем способ защиты данных в Linux - «Новости»
- © F#ck da Antivirus. Как обходить антивирус при пентесте - «Новости»
- © Распуши пингвина! Разбираем способы фаззинга ядра Linux - «Новости»
- © Музыка в пакете. Автоматически конвертируем и аннотируем аудиофайлы в Windows - «Новости»
- © Крадущийся питон. Создаем простейший троян на Python - «Новости»
- © HTB Pit. Находим и эксплуатируем службу SNMP - «Новости»
|
|
|
|
АВТОРИЗАЦИЯ
|
• Мы информационный портал, на котором публикуются новости веб-дизайна и мелкие хитрости, а так же информация и советы которые вам смогут помочь по созданию сайтов, шаблонов, и многое другое. Вы также сможете найти интересные уроки по CSS3, HTML5, jQuery, Photoshop и и многое другое, интересное, с интернет мира. Вся информация размещенная на сайте предназначена исключительно в ознакомительных целях и ошибки в учении не кто не отменял .. Как говориться - "Не бойся, когда не знаешь: страшно, когда знать не хочется." «Самоучитель CSS » → © Мы транслируем с 2006 года. Все для веб-дизайнера - CSS. Все материалы публикуют на сайте гости и пользователи сайта. Администрация сайта не несет ответственности за публикации. |

|