Учебник CSS
Невозможно отучить людей изучать самые ненужные предметы.
Введение в CSS
Преимущества стилей
Добавления стилей
Типы носителей
Базовый синтаксис
Значения стилевых свойств
Селекторы тегов
Классы
CSS3
Надо знать обо всем понемножку, но все о немногом.
Идентификаторы
Контекстные селекторы
Соседние селекторы
Дочерние селекторы
Селекторы атрибутов
Универсальный селектор
Псевдоклассы
Псевдоэлементы
Кто умеет, тот делает. Кто не умеет, тот учит. Кто не умеет учить - становится деканом. (Т. Мартин)
Группирование
Наследование
Каскадирование
Валидация
Идентификаторы и классы
Написание эффективного кода
Самоучитель CSS
Вёрстка
Изображения
Текст
Цвет
Линии и рамки
Углы
Списки
Ссылки
Дизайны сайтов
Формы
Таблицы
CSS3
HTML5
Новости
Блог для вебмастеров
Новости мира Интернет
Сайтостроение
Ремонт и советы
Все новости
Справочник CSS
Справочник от А до Я
HTML, CSS, JavaScript
Афоризмы
Афоризмы о учёбе
Статьи об афоризмах
Все Афоризмы

- 18 декабря 2025, 07:17

| Помогли мы вам |


- 18 декабря 2025, 07:17

- 09 декабря 2025, 15:14
HTB Health. Эксплуатируем SSRF от первоначального доступа до захвата хоста - «Новости»
Hack The Box. Сложность задачи оценена ее авторами как средняя.
warning
Подключаться к машинам с HTB рекомендуется только через VPN. Не делай этого с компьютеров, где есть важные для тебя данные, так как ты окажешься в общей сети с другими участниками.
Разведка
Сканирование портов
Добавляем IP-адрес машины в /:
10.10.11.176 health.htb
Справка: сканирование портов
Сканирование портов — стандартный первый шаг при любой атаке. Он позволяет атакующему узнать, какие службы на хосте принимают соединение. На основе этой информации выбирается следующий шаг к получению точки входа.
Наиболее известный инструмент для сканирования — это Nmap. Улучшить результаты его работы ты можешь при помощи следующего скрипта:
ports=$(nmap -p- --min-rate=500 $1 | grep^[0-9] | cut -d '/' -f 1 | tr 'n' ',' | sed s/,$//)nmap -p$ports -A $1Он действует в два этапа. На первом производится обычное быстрое сканирование, на втором — более тщательное сканирование, с использованием имеющихся скриптов (опция -A).
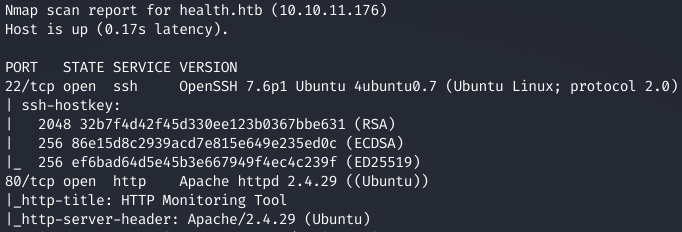
Скрипт нашел два открытых порта: 22 — служба OpenSSH 7.6p1 и 80 — веб‑сервер Apache 2.4.29. Сразу идем на веб‑сервер.
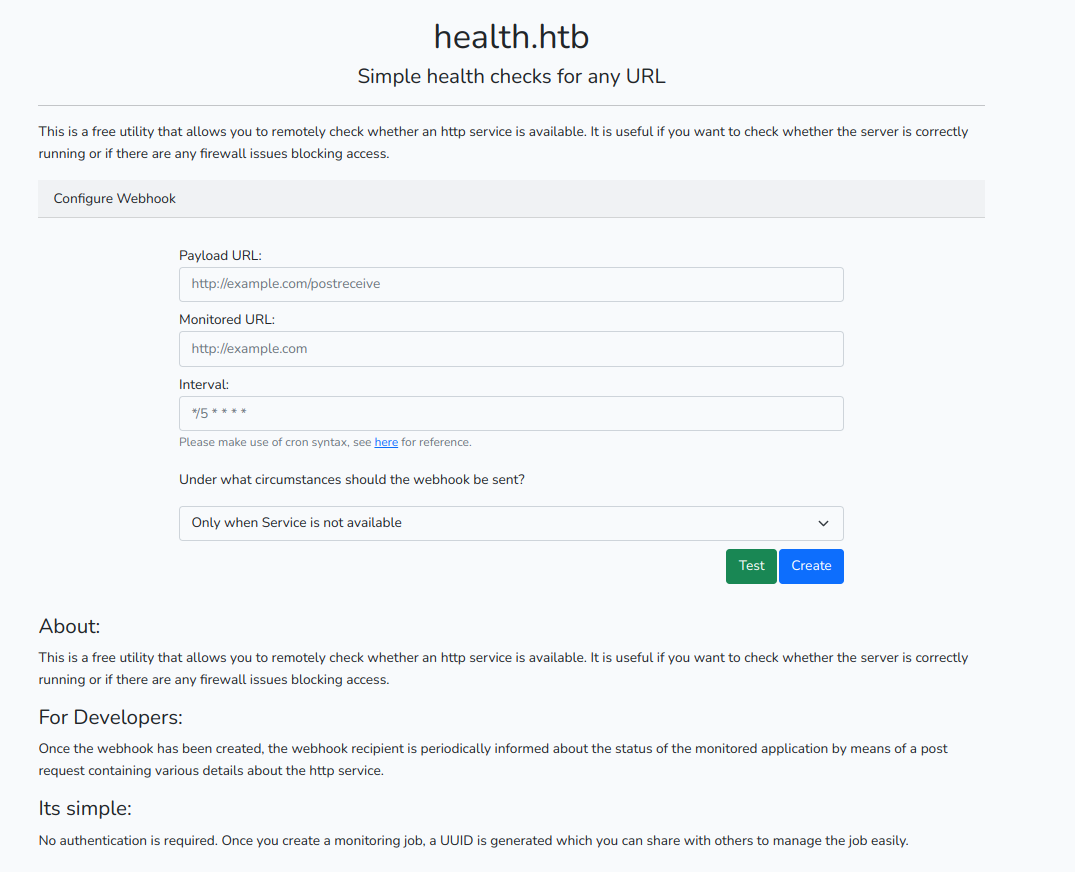
Точка входа
Давай заполним необходимые поля и отправим данные. В полях URL можно указать адрес своего веб‑сервера. Предварительно запустим его:
python3 -m http.server 8080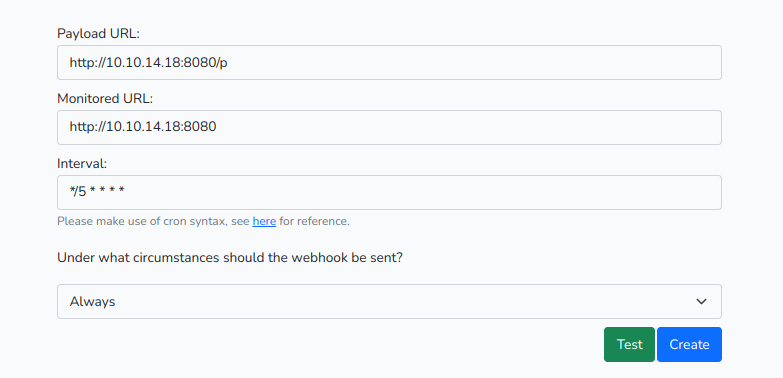

В логах веб‑сервера видим два запроса. Первый — это GET-запрос на указанный Monitored URL, а второй — POST-запрос на Payload URL. Так как http. не показывает нам полные данные, нужно написать свою реализацию. Давай напишем программу, которая будет выводить HTTP-заголовки, а в случае с POST-запросом — еще и переданные данные.
from http.server import BaseHTTPRequestHandler, HTTPServerimport loggingclass Serv(BaseHTTPRequestHandler): def do_GET(self): print("GET " + str(self.path)) print(str(self.headers)) self.send_response(200) self.send_header('Content-type', 'text/html') self.end_headers() def do_POST(self): content_length = int(self.headers['Content-Length']) post_data = self.rfile.read(content_length) print("POST " + str(self.path)) print(str(self.headers)) print(post_data.decode('utf-8')) self.send_response(200) self.send_header('Content-type', 'text/html') self.end_headers() def log_message(self, format, *args): returnlogging.basicConfig(level=logging.INFO)httpd = HTTPServer(('', 8080), Serv)httpd.serve_forever()httpd.server_close()Запускаем и делаем повторный запрос.
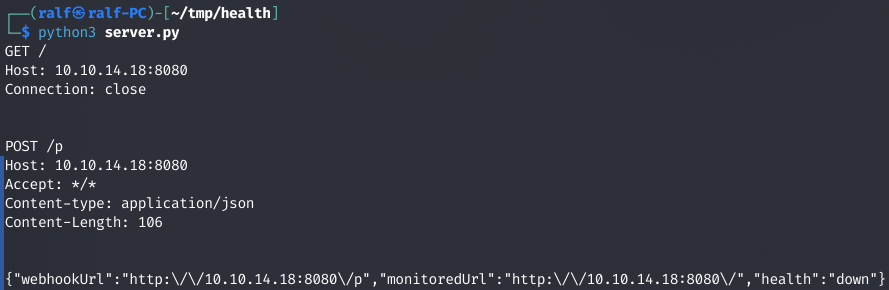
Видим, что в данных POST-запроса передается информация об указанных URL, а также пометка down. Давай попробуем дать какой‑нибудь ответ на GET-запрос. Для этого изменим метод do_GET:
class Serv(BaseHTTPRequestHandler): def do_GET(self): print("GET " + str(self.path)) print(str(self.headers)) self.send_response(200) self.send_header('Content-type', 'text/html') self.end_headers() self.wfile.write("<test>RALF_SERVER<test>".encode('utf-8'))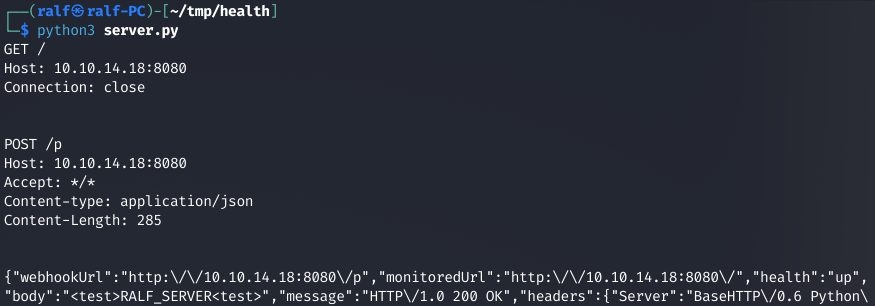
И теперь видим, что в данных POST-запроса нам передают наш же ответ на GET-запрос. Значит, нужно проверить, нет ли здесь возможности для эксплуатации SSRF — то есть возможности подделки запросов.
Точка опоры
SSRF
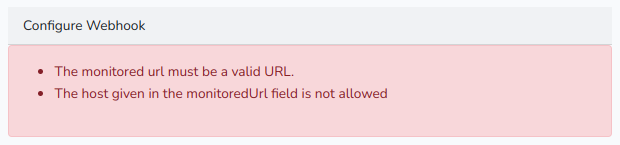
Первым делом я попробовал добраться до файла /, для чего указал в качестве URL file:///, но получил следующее предупреждение.
- © HTB OpenSource. Атакуем удаленный хост через Git - «Новости»
- © HTB Support. Проводим классическую атаку RBCD для захвата домена - «Новости»
- © HTB Secret. Раскрываем секрет JWT - «Новости»
- © HTB RedPanda. Обходим фильтр при Spring SSTI - «Новости»
- © HTB RouterSpace. Повышаем привилегии через баг в sudo - «Новости»
- © HTB Knife. Эксплуатируем нашумевший бэкдор в языке PHP - «Новости»
- © HTB Driver. Эксплуатируем PrintNightmare и делаем вредоносный SCF - «Новости»
- © HTB Forge. Эксплуатируем SSRF для доступа к критической информации - «Новости»
- © HTB Backdoor. Взламываем сайт на WordPress и практикуемся в разведке - «Новости»
- © HTB Bolt. Эксплуатируем шаблоны в Python и разбираемся с PGP - «Новости»
|
|
|
|
АВТОРИЗАЦИЯ
|
• Мы информационный портал, на котором публикуются новости веб-дизайна и мелкие хитрости, а так же информация и советы которые вам смогут помочь по созданию сайтов, шаблонов, и многое другое. Вы также сможете найти интересные уроки по CSS3, HTML5, jQuery, Photoshop и и многое другое, интересное, с интернет мира. Вся информация размещенная на сайте предназначена исключительно в ознакомительных целях и ошибки в учении не кто не отменял .. Как говориться - "Не бойся, когда не знаешь: страшно, когда знать не хочется." «Самоучитель CSS » → © Мы транслируем с 2006 года. Все для веб-дизайнера - CSS. Все материалы публикуют на сайте гости и пользователи сайта. Администрация сайта не несет ответственности за публикации. |

|