Учебник CSS
Невозможно отучить людей изучать самые ненужные предметы.
Введение в CSS
Преимущества стилей
Добавления стилей
Типы носителей
Базовый синтаксис
Значения стилевых свойств
Селекторы тегов
Классы
CSS3
Надо знать обо всем понемножку, но все о немногом.
Идентификаторы
Контекстные селекторы
Соседние селекторы
Дочерние селекторы
Селекторы атрибутов
Универсальный селектор
Псевдоклассы
Псевдоэлементы
Кто умеет, тот делает. Кто не умеет, тот учит. Кто не умеет учить - становится деканом. (Т. Мартин)
Группирование
Наследование
Каскадирование
Валидация
Идентификаторы и классы
Написание эффективного кода
Самоучитель CSS
Вёрстка
Изображения
Текст
Цвет
Линии и рамки
Углы
Списки
Ссылки
Дизайны сайтов
Формы
Таблицы
CSS3
HTML5
Новости
Блог для вебмастеров
Новости мира Интернет
Сайтостроение
Ремонт и советы
Все новости
Справочник CSS
Справочник от А до Я
HTML, CSS, JavaScript
Афоризмы
Афоризмы о учёбе
Статьи об афоризмах
Все Афоризмы

- 18 декабря 2025, 07:17

| Помогли мы вам |


- 18 декабря 2025, 07:17

- 09 декабря 2025, 15:14
Глобальный сбой Cloudflare произошел не из-за атаки, а из-за ошибки - «Новости»
Глава компании Cloudflare Мэттью Принс (Matthew Prince) рассказал о причинах масштабного сбоя, который затронул глобальную сеть компании и многие сайты 18 ноября 2025 года. По его словам, причиной стала ошибка при изменении прав доступа к базе данных, хотя поначалу в компании решили, что столкнулись с масштабной DDoS-атакой.
Принс пишет, что проблема возникла при обновлении прав доступа в кластере ClickHouse, который генерирует feature file для системы Bot Management. Такой файл описывает активность и поведение вредоносных ботов, распространяя эту информацию по всей инфраструктуре Cloudflare, чтобы софт, управляющий маршрутизацией, знал о новых угрозах.
Целью изменения прав было предоставление пользователям доступа к низкоуровневым данным и метаданным. Однако в запросе, который использовался для извлечения этих данных, была допущена ошибка — он возвращал лишнюю информацию. Это более чем вдвое увеличило размер feature file. Когда он превысил установленный лимит, система обнаруживала недопустимо большой файл, после чего работа завершалась сбоем.
Ситуацию усугубило то, что кластер генерировал новую версию файла каждые пять минут. При этом «испорченные» данные появлялись только при запросе к тем нодам, которые уже получили обновление прав. В результате система то работала, то снова отказывала (в зависимости от того на какую ноду попадал запрос, и какой файл уходил в раздачу).
«Эти колебания не давали нам понять, что происходит, поскольку вся система то восстанавливалась, то снова выходила из строя, ведь в нашу сеть попадали то хорошие, то “плохие” файлы конфигурации. Поэтому сначала мы решили, что это атака», — признается Принс.
Периодические сбои в работе Cloudflare начались около 11:20 UTC 18 ноября 2025 года, а уже к 13:00 все ноды ClickHouse стали генерировать «плохие» файлы, и система вошла в «стабильное состояние отказа», после чего серьезные проблемы начались уже у клиентов.
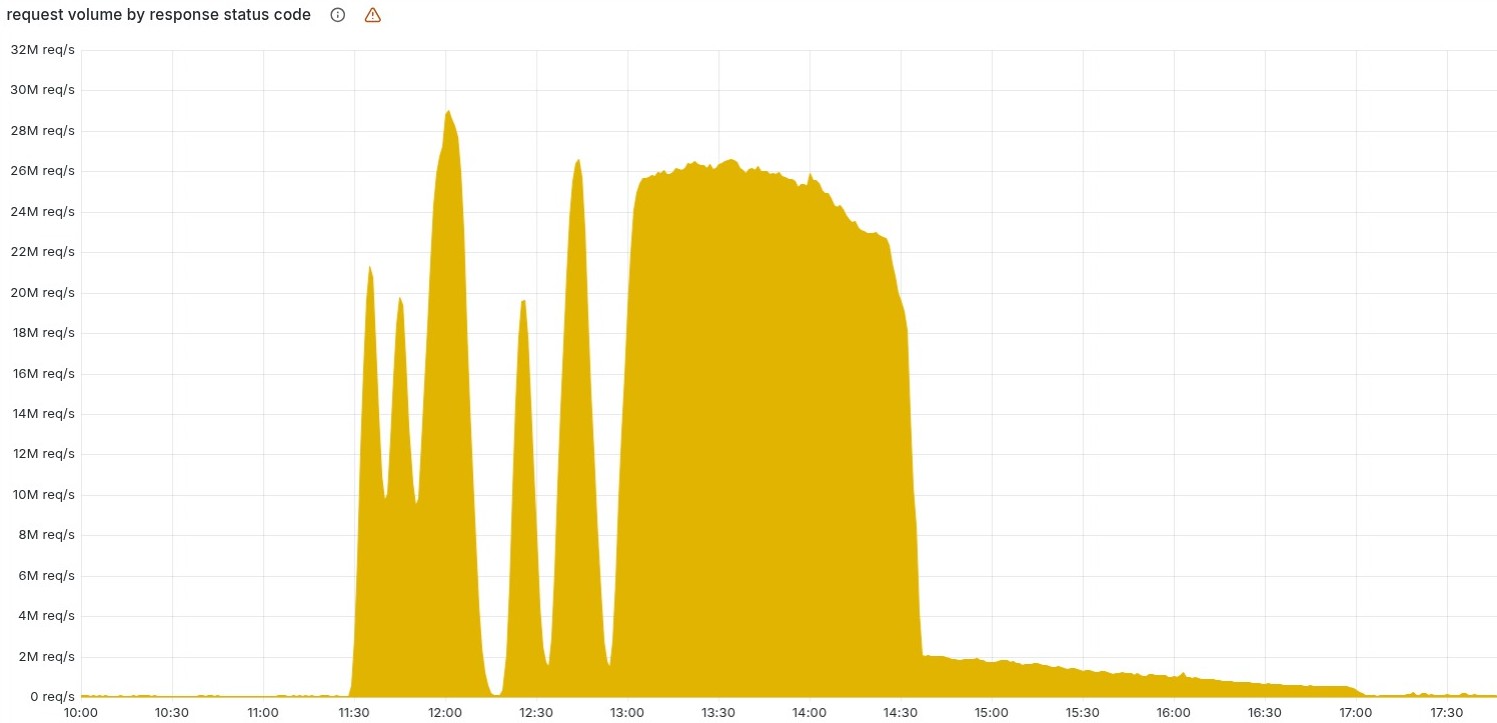
По данным СМИ, не работали ноды Cloudflare по всей Европе, включая Амстердам, Берлин, Франкфурт, Варшаву, Вену, Цюрих, Стокгольм и другие города. Downdetector зафиксировал десятки тысяч жалоб на проблемы с сайтами и хостингом. Попутно пользователи сообщали о сбоях в работе Spotify, Twitter, OpenAI, Anthropic, AWS и Google и множества других сервисов.
Для устранения проблемы команда Cloudflare остановила генерацию «плохих» файлов, вручную добавила в очередь заведомо хороший файл и принудительно перезапустила основной прокси. Полное восстановление заняло около шести часов, и в 17:44 UTC все сервисы заработали в штатном режиме.
В своем сообщении Принс отмечает, что это был самый масштабный сбой в работе компании с 2019 года. Он принес всем извинения «за ту боль, которую мы причинили интернету». По его словам, подобные проблемы недопустимы, и теперь компания планирует усилить валидацию конфигурационных файлов, добавить больше механизмов для экстренного отключения функций, а также пересмотреть логику обработки ошибок во всех основных модулях прокси.
- © Вышли обзоры GeForce RTX 5070 Ti — аналог GeForce RTX 4080 Super с более мощным ИИ-генератором кадров - «Новости сети»
- © Специалисты Cloudflare объяснили, что происходит с российским трафиком - «Новости»
- © DDoS с усилением. Обходим Raw Security и пишем DDoS-утилиту для Windows - «Новости»
- © «Достойная производительность, не лучшая стоимость»: вышли обзоры Intel Arc B570 - «Новости сети»
- © HTB Timelapse. Атакуем Windows Remote Management и работаем с сертификатами - «Новости»
- © Учёные измерили предел разрешения глаза и объяснили, есть ли смысл в 8K-телевизорах - «Новости сети»
- © Новые миссии, аномалии и оптимизация: GSC рассказала, как будет улучшать S.T.A.L.K.E.R. 2: Heart of Chornobyl за оставшиеся месяцы 2025 года - «Новости сети»
- © Зафиксирована мощнейшая DDoS-атака в истории интернета - «Интернет и связь»
- © Лучшие сайты портфолио для вдохновения - «Дизайны сайтов»
- © Лучшие флеш сайты 2016 (45 красивых проектов) - «Веб-дизайн»
|
|
|
|
АВТОРИЗАЦИЯ
|
• Мы информационный портал, на котором публикуются новости веб-дизайна и мелкие хитрости, а так же информация и советы которые вам смогут помочь по созданию сайтов, шаблонов, и многое другое. Вы также сможете найти интересные уроки по CSS3, HTML5, jQuery, Photoshop и и многое другое, интересное, с интернет мира. Вся информация размещенная на сайте предназначена исключительно в ознакомительных целях и ошибки в учении не кто не отменял .. Как говориться - "Не бойся, когда не знаешь: страшно, когда знать не хочется." «Самоучитель CSS » → © Мы транслируем с 2006 года. Все для веб-дизайнера - CSS. Все материалы публикуют на сайте гости и пользователи сайта. Администрация сайта не несет ответственности за публикации. |

|